보이스/코드
정규화
3차 정규화도 여러가지 이상이 존재합니다. 그렇다면 이상이 발생하지
않는 정규화 과정은 어떤거냐고 의문을 가지는 분도 있을 겁니다. 이상이 발생하지 않는 정규화는 키/도메인 정규화입니다. 이것은 증명은 되었으나, 키/도메인 정규화 테이블을 만드는 구체적인 방법을 발견하지 못했기
때문에 실무에서 직관적으로 사용되는 방법이기도 합니다. 그러나 보통 실무에서는 3차 정규화과정이나
다음에 할 보이스/코드 정규화까지 합니다. 그 이유는 일반적으로 4차 정규화나 5차 정규화 과정을 거쳐야 하는 상황은 거의 발생하지
않기 때문입니다. 이 책에서는 보이스/코드 정규화 과정까지만
언급하겠습니다. 만약 보이스/코드 정규화 과정을 거쳤으나
사용자가 원하는 작업을 수행할 때 이상이 발생한다면 4차 정규화 과정을 거쳐야 할 것입니다. 4차, 5차 정규화는 다른 책을 참고하셔야 할 것입니다.
이제 위의 3차
정규화를 거친 테이블에 대한 이상현상이 발생하는 원인을 분석하고 보이스/코드 정규화에 대해서 언급하도록
하겠습니다.
3차 정규화 과정을 거치 테이블에서 이상현상을 발생시키는 원인은 후보키들이 중첩되어 있다는 것 때문입니다. 후보키는 기본키가 될 수 있는 자격이 있는 속성 또는 속성들입니다. 즉, 하나의 릴레이션에 여러 개의 후보키가 존재하는데 하나 또는 여러 개의 속성이 중첩되어서 후보키될 때 이상현상이
발생할 수 있다는 것입니다. 보이스/코드 정규화 과정은 바로
이러한 문제점을 해결하는 것입니다. 이러한 의미에서 볼 때 보이스/코드
보이스/코드
<박스>
-. 하나의 과목을 여러 교수가 담당할 수 있다.
-. 각 교수는 하나의 과목만을 담당한다.
-. 각각의 학생은 같은 과목명을 가진 다른 과목을 수강하지 못한다.
</박스>

<그림 4_84.jpg>
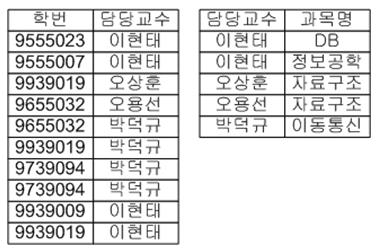
앞서서 언급한 3차
정규화의 문제점인 후보키의 일부가 되는 속성인 “학번”이
중첩되어 있는 것이 보입니다. 즉, 수강_교수 릴레이션의 후보키는 “학번 +
과목명” , “학번 + 담당교수” 입니다. 이 후보키중 “학번 + 과목명”을 기본키라고 가정하겠습니다. 함수 종속 다이어그램에서 보는 바와 같이 “학번 + 과목명”은 “담당교수”를 결정하고, “담당교수”는
“과목명”을 결정합니다. 이런
구조를 가지고 있는 릴레이션의 문제점을 파악해 보도록 하겠습니다.
<박스>
삽입이상:
만약
삭제이상:
학번이 “9655032” 인
학생이 자료구조의 수강 취소를 한다면 오용선 교수가 자료구조를 담당하고 있다는 사실도 함께 삭제됩니다. 이
뿐만 아니라 다른 과목들도 마찬가지로 수강하는 학생이 수강을 취소한다면 과목에 대한 담당교수도 같이 삭제되므로 이상현상이 일어납니다. 만약 다른 수강 신청자가 있다면 이와 같은 사실은 같이 삭제되지 않으나 현재 상황으로 볼 때 어떤 교수가 어떤
과목을 담당하고 있는지를 나타내는 것이 한 개의 투플(행)뿐이기
때문에 이러한 문제를 해결되어야 합니다.
갱신이상:
만약
</박스>
이러한 문제점은 보이스/코드
정규화 과정을 거치면 해결되는 문제입니다. 즉, “모든 결정자가
후보키” 가 되게 하면 되는 것입니다. 다음은 보이스/코드 정규화의 결과입니다.
<그림 4_85.jpg>
이제 여러분은 1차
정규화에서 3차 정규화 까지를 종합적으로 살펴볼 필요가 있습니다. 즉, 이러한 원리만 알고 있다면 바로 3차 정규화 또는 보이스/코드 정규화까지 직접 도출이 가능합니다. 직접 도출하는 예를 들어 보겠습니다. 다음과
같은 스키마가 존재하다고 가정하겠습니다.
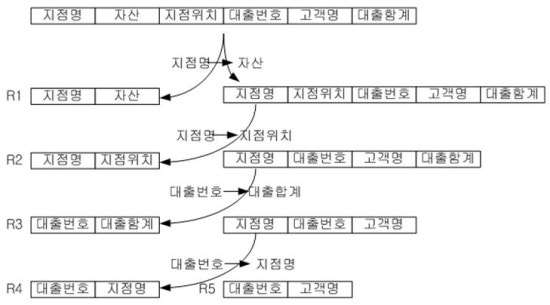
대출 (대출번호, 고객명, 지점명, 지점위치, 자산, 대출합계)
이 스카마는 어떤 은행은 대출에 관련된 스키마입니다. 이 스키마를 가지고 함수적 종속만 파악한다면 나머지 보이스/코드
<함수적 종속>
지점명 à 자산
지정명 à 지점위치
대출번호 à 대출합계
대출번호 à 지점명
<그림 4_86.jpg>
도출한 R1, R2,
R3, R4, R5는 모두 보이스/코드
결과적으로 R1(지점명, 자산),
R2(지점명, 지점위치), R3(대출번호, 대출합계), R4(대출번호, 지점명), R5(대출번호, 고객명)으로 일단은 테이블을 최대한 분해하였습니다. 그러나 R1과 R2는 기본키가 같으므로 통합할 수 있습니다. 그러므로 R1_2 (지점명, 자산, 지점위치) 로 통합되고, R3와 R4, R5가 기본키가 같으나 R3, R4와 R5는 은행(R3, R4)과 고객(R5)으로
서로 다른 것을 나타내므로 R3와 R4는 통합되고, R5는 독립적으로 존재하게 됩니다. 즉, (R3, R4)와 R5는 표현하려는 정보가 틀리기 때문에 통합이
불가능합니다. 마지막에 나온 R5는 원래 정규화되기 전의
원래 테이블의 기본키가 됩니다. 결과적으로 다음과 같이 보이스/코드
정규화가 이루어졌습니다.
R1_2 (지점명, 자산, 지점위치)
R3_4 (대출번호, 지점명, 대출합계)
R5 (대출번호, 고객명)
출처 : 데이터베이스넷
[출처] 보이스/코드 정규화|작성자 톡



