http://technet.microsoft.com/ko-kr/sysinternals/bb896653%28en-us%29.aspx
'분류 전체보기'에 해당되는 글 145건
- 2010.10.28 Process Explorer v12.04 1
- 2010.09.06 pdf 내용 수정 1
- 2010.09.02 [펌] 사용금지: VC 프로젝트 네임 컨버터 (VC Project Name Converter) 1
- 2010.09.01 [펌] USB 키보드 사용시 종류 강제로 바꾸는 방법 1
- 2010.08.30 파일명 검색 툴 everything
- 2010.08.30 PDFCreator- PDF 생성툴 freeware
- 2010.08.23 [My] 정규화 요약 1
- 2010.08.23 [펌] 정규화 1
- 2010.08.23 [펌] 보이스/코드 정규화 1
- 2010.08.23 [펌] 정규화 2
- 2010.08.23 [펌] 정규화(1,2,3정규화 사례)
- 2010.08.10 Flexible Display Center at ASU 1
- 2010.08.08 [펌] 객체지향을 왜 배워야 하는가? 1
- 2010.08.08 [펌] TAction을 활용하자.
- 2010.08.08 [펌] 델파이 객체지향프로그래밍을 위한 20가지 규칙 1
- 2010.08.03 [펌] MSDN: 개발자로서의 자부심 1
- 2010.07.21 UML Version별 Release시기.
- 2010.07.19 IP Hider - proxy를 쉽게 해 주는 툴 2
- 2010.07.19 [펌] 개인과외소득신고-개인과외교습자소득신고에 관하여 낙서장 2009/08/13 01:09 복사 http://blog.naver.com/susieye/60088331932
- 2010.07.19 [펌] 젠더의 차이를 이해하라! 1
- 2010.07.14 [펌] 세계 반도체 장비 산업 현황 (2002년) 1
- 2010.07.09 세마포어 [ semaphore ] 2
- 2010.07.09 뮤텍스 [ Mutex, Mutual Exclusion object ] 1
- 2010.07.09 [펌] Override Vs. Overload
- 2010.07.08 [펌] 취업시 개발자(프로그래머)들이 피해야 할 회사
- 2010.07.07 UML1.3 vs UML2.0 2
- 2010.07.07 UML 2.2 : diagram 종류는 14개(=7+7) 1
- 2010.07.07 Stack & heap 5 1
- 2010.07.07 Stack & heap 4- 최고의 설명(간만) 2
- 2010.07.07 Stack & heap 3 - in Unix
http://technet.microsoft.com/ko-kr/sysinternals/bb896653%28en-us%29.aspx
My 요약:
TouchUp 텍스트 도구
1.[도구] > [고급 편집] > [TouchUp 텍스트 도구]를 선택하거나 [고급 편집[ 도구 모음에서 [TouchUp 텍스트] 도구 를 선택한다.
2.편집할 텍스트를 클릭합니다. 선택 가능한 텍스트 주위에 테두리 상자가 생긴다.
출처: http://cafe.naver.com/sunciayi.cafe?iframe_url=/ArticleRead.nhn%3Farticleid=1536
출처: http://www.sungyujin.co.kr/system/textyle/6744
TouchUp 텍스트 도구
1.[도구] > [고급 편집] > [TouchUp 텍스트 도구]를 선택하거나 [고급 편집[ 도구 모음에서 [TouchUp 텍스트] 도구 를 선택한다.
2.편집할 텍스트를 클릭합니다. 선택 가능한 텍스트 주위에 테두리 상자가 생긴다.
출처: http://cafe.naver.com/sunciayi.cafe?iframe_url=/ArticleRead.nhn%3Farticleid=1536
출처: http://www.sungyujin.co.kr/system/textyle/6744
입력도구

1.[도구] > [입력 도구] > [입력 도구 모음 표시]를 선택한 다음 [입력 도구] 단추를 클릭한다.
2.입력할 위치를 클릭한 다음 입력을 시작한다. 두 번째 행을 추가하려면 Enter 키를 누른다.
3.텍스트 속성을 변경하려면 해당 텍스트를 선택하고 [입력] 도구 모음에서 다음과 같은 도구를 사용한다.
■텍스트 크기를 변경하려면 [텍스트 크기 축소] 단추 또는 [텍스트 크기 증가] 단추를 클릭, 또는 팝업 메뉴에서 서체 크기를 선택한다.
■줄 간격(행간)을 변경하려면 [줄 간격 줄이기] 단추 또는 [줄 간격 늘리기] 단추를 클릭한다.
■[텍스트 색상] 팝업 메뉴에서 색상을 선택한다.
■[서체] 팝업 메뉴에서 서체를 선택한다.
4.입력 텍스트 블록을 옮기거나 크기를 조정하려면 [선택 도구]를 선택하고 입력 텍스트 블록을 클릭한 다음 텍스트 블록 또는 블록의 모서리를 마우스로 끈다.
5.텍스트를 다시 편집하려면 [입력 도구]를 선택한 다음 입력 텍스트를 두 번 클릭한다.
입력 도구 사용
고급 편집

입력 도구 가 기존 문서에 텍스트를 새로 입력하는 도구 라면, 고급 편집 메뉴는 기존 문서의 텍스트나 이미지 개체를 이동 하거나, 기존 문서의 텍스트를 수정 하는 도구다.
TouchUp 텍스트 도구
1.[도구] > [고급 편집] > [TouchUp 텍스트 도구]를 선택하거나 [고급 편집[ 도구 모음에서 [TouchUp 텍스트] 도구 를 선택한다.
2.편집할 텍스트를 클릭합니다. 선택 가능한 텍스트 주위에 테두리 상자가 생긴다.
3.편집할 텍스트를 선택한다.
■테두리 상자 내의 모든 텍스트를 선택하려면 [편집] > [전체 선택]을 선택한다.
■마우스를 끌어 문자, 공백, 단어 또는 줄을 선택한다.
4.다음 중 하나를 수행하여 텍스트를 편집한다.
■선택한 텍스트를 바꾸려면 새 텍스트를 입력한다.
■텍스트를 제거하려면 Delete 키를 누르거나 편집 > [삭제]를 선택한다.
■선택한 텍스트를 복사하려면 [편집] > [복사]를 선택한다.
■텍스트를 마우스 오른쪽 단추로 클릭하고 적절한 옵션을 선택한다.
선택을 취소하고 다시 시작하려면 선택한 텍스트가 아닌 다른 곳을 클릭한다.
텍스트 특성 편집
1.[TouchUp 텍스트 도구]를 선택한다.
2.편집할 텍스트를 클릭한다.
3.텍스트를 마우스 오른쪽 단추로 클릭하고 [속성]을 선택한다.
4.[TouchUp 속성] 대화 상자에서 [텍스트] 탭을 선택, 다음의 텍스트 특성을 변경할 수 있다.
글꼴 : 선택한 텍스트에 사용된 글꼴을 지정한 글꼴로 변경한다.
시스템에 설치되어 있거나 PDF 문서에 완전히 포함된 모든 글꼴을 선택할 수 있다.
글꼴 목록에서 문서 글꼴은 위쪽에 표시되고 시스템 글꼴은 아래쪽에 표시된다.
글꼴 크기 : 글꼴 크기를 지정한 크기(포인트 단위)로 변경한다.
글자 간격 : 선택한 텍스트 내의 둘 이상의 문자 사이에 일정한 간격을 둔다.
단어 간격 : 선택한 텍스트에 있는 둘 이상의 단어 사이에 일정한 간격을 둔다.
가로 비율 : 글꼴의 높이와 너비 간 비율을 지정한다.
기준선 오프셋 : 텍스트를 기준선에서 오프셋한다. 기준선은 해당 글꼴을 배치할 때 기준으로 사용되는 선이다.
채우기 : 채우기 색상을 지정한다.
선 : 선 색상을 지정한다.
선 너비 : 선 두께를 지정한다.
참고: 특정 글꼴이 사용된 텍스트를 수정하려면 법적인 문제가 발생하지 않도록 글꼴을 구입해 시스템에 설치해야 합니다.
TouchUp 개체도구 의 개체 이동 또는 편집
개체도구 는 개체 (삽입된 이미지, 영상, 텍스트 등 문서내 모든 오브젝트) 를 선택 후 이동 또는 편집 (마우스 오른쪽 텝메뉴) 이 가능하다.
각각의 도구는 마우스 오른쪽 메뉴에 추가 기능이 포함되 있다.
고급 편집 메뉴 사용 예
지금까지 설명한 방법은, PDF 문서의 직접 수정 방법이다.
직접 수정 방법 이외에도 PDF 문서는 주석 및 마크업 등을 통해 타인과의 교정 및 수정 작업을 문서 내에 의견 수렴을 표시 하며 작업 할 수 있다.
주석 및 마크업 도구는, 예를 들어, 형광펜이나 빨간펜으로 밑줄을 그어 가며 오타나 문법 수정을 해서 문서 작성자에게 다시 보내 주는 것을 상상 하면 된다.
(디지털 문서가 아닌, 출력된 문서 상으론 익숙한 방법일 것이다. 그것을 Adobe Acrobat 을 통해 사용할 수 있다. )
출처: http://blog.acrobatexpert.com/acrobat/1826
My) 결론 : 사용금지
(원래 도스모드 파일을 이용하는 유틸이 있는데, 지금 당장 구할 수 없어서 인터넷에서 이걸 찾아서 시도했으나 fail)
출처: http://www.devpia.com/MAEUL/Contents/Detail.aspx?BoardID=278&MAEULNo=20&no=18208&ref=18208
 VCProjectConverter_Install.exe
VCProjectConverter_Install.exeVisual C++ 6.0 프로젝트 또는 Borland C++ Builder의 프로젝트 이름을 변경할 필요가 있는 경우에 다음 프로그램을 사용하면 됩니다.
한번 실행하고 나면 확장자에 dsw, dsp, bpg, bps 등의 확장자에 Clean Project와 Convert New Project 라는 메뉴가 연결되어 나옵니다.
프로젝트가 복사될 경로와 변경할 키워드를 설정해 주시면, 새로운 경로에 새로운 이름으로 프로젝트 명이 변경되어 복사됩니다.
새로 생성된 프로젝트는 꼭 Rebuild All을 하셔야 합니다.
확장자 명이 연결이 안되어 있는 경우에도 프로젝트 경로의 파일을 소스쪽에 드래그앤 드롭한 후에 대상 경로와 바뀔키워드를 지정하시면 변경이 됩니다.
복사시에 필요없는 파일은 지우고 복사할 수 있는 옵션을 두었습니다.
혹시 문제가 발생할지 모르니 프로젝트는 반드시 백업을 하고 사용하시기 바랍니다.




- 모든
파일의 특정 키워드가 바뀌도록 되어 있습니다.
때로는 원치 않는 것도 바뀔수 있으니 참고하시기 바랍니다.
DIALOG의 이름이 바뀌어 컴파일이 안되는 경우에는 앞뒤의 큰따옴표(") 를 지우고 이름을 다시 재정리후 컴파일 하면 잘되는 경우도 있습니다.
출처: http://mastmanban.tistory.com/419
USB 키보드 사용시 종류 강제로 바꾸는 방법
키
보드 타입에는 예전부터 많이 쓰이던 PS2 방식과 요즘 많이 쓰는 USB 타입이 있습니다. PS2 방식으로 사용되는 키보드에선
키보드 드라이버에서 종류를 변경할수 있지만 USB 키보드를 사용하면 변경 할수가 없습니다. 윈도우에서 기본 드라이버를 지원하지
않더군요. 그리고 설정 하는 방법도 없었습니다.

그
리고 요즘 나오는 컴퓨터를 보니 PS2 방식이 본체에 아예 없는 컴퓨터도 있습니다. 그러니 USB 키보드를 사용하면서 윈도우 처음
설치시 나오는 키보드 종류 고르는 곳에서 1번(A형) 을 선택하신 분들은 다른 종류로 바꿀 방법이 없습니다. 하지만 늘 그렇듯 방법이 아예 없는건 아니죠. 좀 불편하긴 하지만 레지스트리 편집기에서 강제로 변경해 주는 방법이 있습니다.
우선 [시작->검색],[시작->실행], [윈도우키+R] 을 이용하여 regedit 를 입력하고 레지스트르 편집기를 실행 시킵니다.

레지스트리 편집기에서 아래의 경로로 이동을 합니다.
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\i8042prt\Parameters

그러면 우측에 보이는 값중에 LayerDriver Kor, OverrideKeyboardIdentifier, OverrideKeyboardSubtype 의 값을 종류에 맞게끔 아래의 표를 참조하여 값을 변경해 주시면 됩니다.
| A(종류1) | B(종류2) | C(종류3) | |
| LayerDriver Kor | kbd101a.dll | kbd101b.dll | kbd101c.dll |
| OverrideKeyboardIdentifier | PCAT_101AKEY | PCAT_101BKEY | PCAT_101CKEY |
| OverrideKeyboardSubtype | 3 | 4 | 5 |
값 변경은 a,b,c 와 3,4,5 만 변경해 주면 되기 때문에 크게 어려운 부분은 아니라 생각 됩니다. 그리고 주의 하실점은 C:\Windows\System32 에 사용하고자 하는 키보드 파일 .dll 이 있는지 꼭 확인을 하셔야 합니다.

이렇게 설정을 마치셨으면 재부팅을 하고 나면 원하는 키보드 종류로 변경되어 있을 것입니다. 확인 방법은 각 키보드 종류별 특징을 테스트해 보면 됩니다.
| 101A(종류1) | 키보드의 한영 키 사용할수 있음 |
| 101B(종류2) | - |
| 101C(종류3) | 키보드의 한영키 대신 Shift-Space 키를 한영 키로 인식 |
101B는 사용하시는 분들을 한번도 보지 못해 어떤 특성이 있는지 잘 모르겠네요. ^^ 전 늘 101A만 사용 했었고 대부분의 사용자들이 101A를 많이 사용하는데 간혹 101C를 사용하시는 분들도 계시더군요. USB 키보드를 사용하면 종류3으로 사용해야 하실 분들은 이 방법을 이용하여 강제 변경을 해보시기 바랍니다.
정규화는,
1) 데이터의 중복을 방지, 효율적인 데이터 저장
-> 논리적으로 작은 단위의 테이블로 분리되어진다.
2) 1차, 2차, 3차, 4차, 5차 정규화까지 있지만,
일반적으로 3차까지만 정규화를 해서 사용한다. 이게 현실적이므로.
1) 데이터의 중복을 방지, 효율적인 데이터 저장
-> 논리적으로 작은 단위의 테이블로 분리되어진다.
2) 1차, 2차, 3차, 4차, 5차 정규화까지 있지만,
일반적으로 3차까지만 정규화를 해서 사용한다. 이게 현실적이므로.
출처: http://blog.naver.com/ngldevilsun?Redirect=Log&logNo=100092625936
- 데이터의 중복을 방지, 효율적인 데이터 저장
-> 논리적으로 작은 단위의 테이블로 분리되어진다.
제 1 정규화
- 반복되는 속성이나 그룹 속성을 제거하고 새로운 실체를 추가한뒤 기존의
실제와 1:N의 관계를 형성한다.
제2 정규화
- 복합키로 구성된 경우 해당 테이블 안의 모든 컬럼들은 복합키 전체에
의존적이어야한다.
만일 복합키 일부에 의존적인 컬럼이 존재한다면 제거해야한다.
복합키가 아닌 경우 제 2 정규화의 대상이 되지 않는다.
N:M 관계
학생 | - 동아리등록 |- 동아리
-학번 | ~ 동아리코드(FK), 학번(FK) | - 동아리 코드
이름, | 등록일자 | 동아리명
주민번호,| 등록사유 | 설립취지
전화번호,| | 설립일자
.....
제3 정규화
- 한테이블 안의 모든 키가 아닌 컬럼들은 기본키(Primary Key)에 의존해야한다.
만일 키가 아닌 컬럼에 종속되는 속성이 존재한다면 이를 제거해야한다.
* 정규화는 순서적으로 하는것이 절대 아니다
1차 정규화에 위배할 경우 정규화함
2차 정규화를 위배하지 않을 경우 할 필요가 없다.
출처: http://naver.kinjsp.pe.kr/140049262165
출처 : 데이터베이스넷
보이스/코드
정규화
3차 정규화도 여러가지 이상이 존재합니다. 그렇다면 이상이 발생하지
않는 정규화 과정은 어떤거냐고 의문을 가지는 분도 있을 겁니다. 이상이 발생하지 않는 정규화는 키/도메인 정규화입니다. 이것은 증명은 되었으나, 키/도메인 정규화 테이블을 만드는 구체적인 방법을 발견하지 못했기
때문에 실무에서 직관적으로 사용되는 방법이기도 합니다. 그러나 보통 실무에서는 3차 정규화과정이나
다음에 할 보이스/코드 정규화까지 합니다. 그 이유는 일반적으로 4차 정규화나 5차 정규화 과정을 거쳐야 하는 상황은 거의 발생하지
않기 때문입니다. 이 책에서는 보이스/코드 정규화 과정까지만
언급하겠습니다. 만약 보이스/코드 정규화 과정을 거쳤으나
사용자가 원하는 작업을 수행할 때 이상이 발생한다면 4차 정규화 과정을 거쳐야 할 것입니다. 4차, 5차 정규화는 다른 책을 참고하셔야 할 것입니다.
이제 위의 3차
정규화를 거친 테이블에 대한 이상현상이 발생하는 원인을 분석하고 보이스/코드 정규화에 대해서 언급하도록
하겠습니다.
3차 정규화 과정을 거치 테이블에서 이상현상을 발생시키는 원인은 후보키들이 중첩되어 있다는 것 때문입니다. 후보키는 기본키가 될 수 있는 자격이 있는 속성 또는 속성들입니다. 즉, 하나의 릴레이션에 여러 개의 후보키가 존재하는데 하나 또는 여러 개의 속성이 중첩되어서 후보키될 때 이상현상이
발생할 수 있다는 것입니다. 보이스/코드 정규화 과정은 바로
이러한 문제점을 해결하는 것입니다. 이러한 의미에서 볼 때 보이스/코드
보이스/코드
<박스>
-. 하나의 과목을 여러 교수가 담당할 수 있다.
-. 각 교수는 하나의 과목만을 담당한다.
-. 각각의 학생은 같은 과목명을 가진 다른 과목을 수강하지 못한다.
</박스>

<그림 4_84.jpg>
앞서서 언급한 3차
정규화의 문제점인 후보키의 일부가 되는 속성인 “학번”이
중첩되어 있는 것이 보입니다. 즉, 수강_교수 릴레이션의 후보키는 “학번 +
과목명” , “학번 + 담당교수” 입니다. 이 후보키중 “학번 + 과목명”을 기본키라고 가정하겠습니다. 함수 종속 다이어그램에서 보는 바와 같이 “학번 + 과목명”은 “담당교수”를 결정하고, “담당교수”는
“과목명”을 결정합니다. 이런
구조를 가지고 있는 릴레이션의 문제점을 파악해 보도록 하겠습니다.
<박스>
삽입이상:
만약
삭제이상:
학번이 “9655032” 인
학생이 자료구조의 수강 취소를 한다면 오용선 교수가 자료구조를 담당하고 있다는 사실도 함께 삭제됩니다. 이
뿐만 아니라 다른 과목들도 마찬가지로 수강하는 학생이 수강을 취소한다면 과목에 대한 담당교수도 같이 삭제되므로 이상현상이 일어납니다. 만약 다른 수강 신청자가 있다면 이와 같은 사실은 같이 삭제되지 않으나 현재 상황으로 볼 때 어떤 교수가 어떤
과목을 담당하고 있는지를 나타내는 것이 한 개의 투플(행)뿐이기
때문에 이러한 문제를 해결되어야 합니다.
갱신이상:
만약
</박스>
이러한 문제점은 보이스/코드
정규화 과정을 거치면 해결되는 문제입니다. 즉, “모든 결정자가
후보키” 가 되게 하면 되는 것입니다. 다음은 보이스/코드 정규화의 결과입니다.
<그림 4_85.jpg>
이제 여러분은 1차
정규화에서 3차 정규화 까지를 종합적으로 살펴볼 필요가 있습니다. 즉, 이러한 원리만 알고 있다면 바로 3차 정규화 또는 보이스/코드 정규화까지 직접 도출이 가능합니다. 직접 도출하는 예를 들어 보겠습니다. 다음과
같은 스키마가 존재하다고 가정하겠습니다.
대출 (대출번호, 고객명, 지점명, 지점위치, 자산, 대출합계)
이 스카마는 어떤 은행은 대출에 관련된 스키마입니다. 이 스키마를 가지고 함수적 종속만 파악한다면 나머지 보이스/코드
<함수적 종속>
지점명 à 자산
지정명 à 지점위치
대출번호 à 대출합계
대출번호 à 지점명
<그림 4_86.jpg>
도출한 R1, R2,
R3, R4, R5는 모두 보이스/코드
결과적으로 R1(지점명, 자산),
R2(지점명, 지점위치), R3(대출번호, 대출합계), R4(대출번호, 지점명), R5(대출번호, 고객명)으로 일단은 테이블을 최대한 분해하였습니다. 그러나 R1과 R2는 기본키가 같으므로 통합할 수 있습니다. 그러므로 R1_2 (지점명, 자산, 지점위치) 로 통합되고, R3와 R4, R5가 기본키가 같으나 R3, R4와 R5는 은행(R3, R4)과 고객(R5)으로
서로 다른 것을 나타내므로 R3와 R4는 통합되고, R5는 독립적으로 존재하게 됩니다. 즉, (R3, R4)와 R5는 표현하려는 정보가 틀리기 때문에 통합이
불가능합니다. 마지막에 나온 R5는 원래 정규화되기 전의
원래 테이블의 기본키가 됩니다. 결과적으로 다음과 같이 보이스/코드
정규화가 이루어졌습니다.
R1_2 (지점명, 자산, 지점위치)
R3_4 (대출번호, 지점명, 대출합계)
R5 (대출번호, 고객명)
출처 : 데이터베이스넷
[출처] 보이스/코드 정규화|작성자 톡
출처 : http://myhome.naver.com/yasicom2/normalization2.htm
|
정규화
우 리는 이제까지 데이터베이스의 설계를 위한 여러가지를 살펴보았습니다. 위에서 다룬 것은 현실을 어떻게하면 가장 근접하게 표현하는가에 대한 고려사항들이였습니다. 이것들은현실을 직관적으로 바라보고, 논리적으로 어떻게 하면 현실을 제대로 데이터베이스에 반영할 것인가에 대한 것이였습니다.
데 이터베이스의 설계에서 가장 중요한 것은 현실을 제대로 반영하는 것이며, 이를 어떻게 논리적으로 구성하는가를 결정하는 것입니다. 특히 관계형 데이터 모델에서는 데이터 값들이 2차원의 평면 테遣?형태로 표현하므로 어떤 릴레이션들이 필요하고, 어떤 애트리뷰트가 필요한가를 결정하는 것이 중요합니다.
이 젠 앞서서 직관적으로 바라보았던 것들을 '정규화'라는 원리를 도입할 것입니다. 정규화는 관계형 데이터 모델에서 아주 중요한 역할을 하고 있습니다. 학자마다 정규화는 튜닝의 도구 또는 설계 검증의 도구이다라고 의견이 약간씩은 다르지만 결국은 같은 의미를 가지고 있습니다. 현실을 제대로 반영하는 것은 튜닝과 검증이라는 것을 모두 포함하고 있기 때문입니다.
데 이터베이스 설계를 할 때 우리는 단계적인 사고방식을 가져야한다고 했습니다. 단계적인 사고 방식에서 윗 단계를 생각해 봅시다. 대부분은 설계의 초기단계에서 복잡한 생각을 하지 않는다고 나중에 누락되지는 않을까 하고 생각하는 분들이 많습니다. 그러나 이러한 것들은 정규화 과정이나 앞의 단계를 거치면서 데이터 모델링은 멋있게 틀을 잡아갑니다. 이렇게 틀을 잡아가는 것중 정규화는 그야말로 아주 큰 역할을 하는 것입니다. 앞에서 행했던 설계를 검증하고, 데이터의 중복을 없앤다 것 자체가 정보의 질을 높이고, 설계의 튜닝을 하는 것이니까요.
정 규화란 속성이 제위치에 제대로 찾아가게끔 하는 것입니다. 정규화의 목적은 당연히 데이터의 중복의 최소화와 여러가지 이상(Anomaly)들을 제거함에 있습니다. 데이터가 중복되어 있으면 여러 문제를 일으킬 수 있습니다. 삽입, 삭제, 변경에서 나타는 이상들이 개발자를 괴롭히는 것입니다. 이것은 결국 속성이 제자리에 있지 않기 때문에 발생하는 중복의 문제점 때문이라고 할 수 있습니다.
정 규화 과정은 속성간에 관계성, 데이터 종속성, 성능, 데이터베이스의일관성 유지등을 고려해야합니다. 정규화를 검증도구라고 하는 것도 설계가 잘못되면 일어날 수 있는 여러가지 문제점을 예방하는 차원이기 때문입니다. 또한 데이터의 중복을 없앤다는 자체가 엄청난 튜닝의 효과를 가지는 것입니다. 일단 데이터의 중복이 많은 설계는 먼가가 문제가 있는 설계입니다. 데이터베이스의 정의에서도 언급했듯이 데이터베이스는 중복의 최소화로 기존의 파일처리방식이나 수작업 방식에서 오는 정보의 질을 떨어뜨리는 문제점을 없애는 것입니다. 이러한 문제점을 좋은 정보의 질을 유지하기 위한 하나의 정형화된 도구 즉, 정규화를 통해 해결을 하게 되는 것입니다.
정 규화는 데이터의 중복으로 인한 문제를 해결하기 위해서 속성들간에 종속성(Dependency)을 분석해서 기본적으로 하나의 릴레이션(테이블)에 표현하도록 분해를 하는 것입니다. 어떻게 보면 테이블을 무작정 쪼개는 것으로 보일 수도 있습니다. 그러나 테이블을 쪼개는 기준은 "함수적 종속"이란 개념으로 쪼개는 것입니다. 즉, 함수적 종속성을 파악한 다음 그 함수적 종속을 기본으로 해서 속성들을 하나의 테이블로 그룹짓는 것입니다.
함수적 종속
그럼 "함수적 종속" 이란 것이 무엇인가 살펴보도록 하겠습니다. 일단 함수라 하면 다음의 그림과 같이 나타낼 수 있습니다.
이것을 테이블로 표현한다면 다음과 같겠지요.
감이 약간 오시나요?? 일단 함수적 종속이란 말에서 함수라는 것에 대해서 살펴보도록 하겠습니다. 함수가 무엇인가요? 다름의 그림을 보고서 설명을 하도록 하겠습니다.
그 림처럼 왼쪽은 2라는 원소가 두개가 들어 있습니다. 2를 어떤 함수에 집어 넣어야지 4가 될까요? 일반적으로 생각해 보면 2의 제곱을 구하는 함수에 값을 집어 넣는다면 4가 되겠지요. 그러나 역으로 4를 집어 넣는다면 16이 되버리는 것입니다. 즉, 2와 2는 4가 되기 위해서 함수적으로 종속되어 있는 것입니다. 결국 4는 2와 2가 4가 되기 위한 함수에 종속적이기 때문에 2의 제곱이라는 함수에 종속적이게 만드는 4는 "결정자"라고 부릅니다. 또한 2와 2를 "종속자"라고 합니다.
사 실 이렇게 수학적으로 함수적 종속을 설명하였으나 정규화는 시스템을 구축하고자하는 조직내의 의미에 함수적 종속을 설명해야 합니다. 즉, 정규화는 관계형 모델에서 표현하고자 하는 주제가 동일한 속성들끼리 뭉쳐져 있는 것입니다. 그러므로 설계의 초기부터 나타내고 자하는 정보를 의미론적으로 묶는다면 정규화라는 과정의 설계의 검증도구가 되는 것입니다.
위의 예에서 2를 Y로 하고 4를 X라 한다면 함수적 종속의 표현은 "X Y" 로 표기합니다. 이러한 표현을 실제의 예를 들어서 살펴보겠습니다.
학생 릴레이션에서 ...
학번 이름 학번 학과 학번 학년
위 에서 보는 바와 같이 학번은 이름, 학과, 학년을 결정하고 있습니다. 즉, 학생 릴레이션에서 각각의 학생을 유일하게 구분지을 수 있는 속성은 학번으로 학번은 기본키의 역할을 하는 속성입니다. 즉, 이름만 가지고는 각각의 학생을 알 수 없다는 것입니다. 제가 옛날에 휴학을 하려고 했는데 시간이 없어서 조교님께 휴학 신청을 대신해달라고 한 적이 있었습니다. 그런데 저와 같은 이름을 가진 다른 사람이 있었는데 그 사람으로 휴학을 한적이 있어서 상당히 난감했던 적이 있습니다. 즉, 저의 이름인 "이재학" 만 가지고는 정확성이 있는 정보가 될 수 없던 것입니다. 만약 교수님께서 "이재학"을 불러오라 라고 한다면 이미 과에 "이재학"이 란 이름을 가진 사람이 2명이라는 것을 아는 사람은 학번을 교수님께 되물을 것입니다. 이렇듯 이름은 학번에 종속되어 있다는 것입니다. 이름이 이재학이고, 학과가 정보통신공학과이고, 4학년인 학생은 저 말고도 한명이 더 있습니다. 즉, 이것들은 학번에 종속적이라는 것입니다.
테이블로 표현한 것을 가지고 좀더 살펴보도록 하겠습니다.
9555023, 이재학, 4학년, 정보통신공학과 라는 것은 한명의 학생에 대햔 데이터입니다. 학번, 이름, 학년, 학과중에 대표성을 띄고 있는 것은 학번이고, [9555023, 이재학], [9555023, 4학년], [9555023, 정보통신] 이라고 해야지만 정확한 정보를 표현할 수가 있는 것이죠. 앞에서 언급했듯이 [이재학, 4학년, 정보통신]이라고 해서 정확한 정보가 되는 것일까요? 당연히 학번이 9555023인 학생과 학번이 9839011인 학생을 구별하지 못하는데 문제가 있습니다.
이렇듯 학번은 이름, 학년, 학과를 결정하고, 이름, 학년, 학과는 학번에 종속적입니다. 이렇게 데이터에 대한 의미를 표현한 것을 함수적 종속이라고 합니다.
<참고> 함수 종속에 대한 증명된 추론 규칙 (R 릴레이션) (데이터베이스시스템, 이석호, 정익사)
R1: (반사규칙) A B 이면 A B 이다. R2: (첨가규칙) A B 이면 AC BC 이고 AC B 이다. R3: (이행규칙) A B 이고 B C 이면 A C 이다. R4: (분해규칙) A BC 이면 A B 이다. R5: (결합규칙) A B 이고 A C 이면 A BC 이다.
정규화는 이러한 "함수적 종속"을 기본 원칙으로 하나의 의미를 가지는 집합으로 나누는 작업입니다. 정규화는 1차 정규화, 2차 정규화, 3차 정규화, 보이스/코드 정규화, 4차 정규화, 5차 정규화, 도메인/키 정규화가 있습니다. 이 순서가 높아지는 단계의 정규화일수록 무결성은 강화되나 과도하게 테이블이 쪼개지므로 쓸 때 없는 부하가 걸릴 수 있습니다. 그러므로 현실을 감안해서 어느 정도 수준의 정규화까지 행해야 하는가를 결정해야 합니다. 보통 실무에서는 3차 정규화와 보이스/코드 정규화까지 합니다. 기본으로 3차 정규화까지는 해야 하며, 3차 정규화 과정을 마치고도 사용자의 요구사항에 의해서 여러가지 이상들이 발생할 요지가 있다면 더 높은 차원의 정규화를 해야 합니다. 이제 각 단계별 정규화에 대해서 설명하도록 하겠습니다.
1차 정규화
하 나의 릴레이션은 어떤 도메인의 집합입니다. 각각의 속성은 해당 도메인에 속하는 단지 하나의 값을 가져야 합니다. 이것이 1차 정규화 이며, 실제로 1차 정규화도 거치지 않은 테이블이 많이 존재합니다. 예를 들면 다중값 속성들이 그대로 표현될 때 정규화된 테이블이 아닌 즉, 비정규화 테이블인 것입니다. 사원테이블에 사번, 이름, 보유기술, 월급의 속성이 있는데 보유기술은 여러 개를 가질 수 있다는 현실을 생각해 보도록 하겠습니다. 일반적으로 문서를 만들면 다음과 같은 문서가 나올 수 있습니다. 보유기술에서 하나의 속성값에 여러 개의 값이 들어간 것을 볼 수 있습니다. 이러한 표현은 비정규화 된 테이블입니다. 여기서 기본키는 사원번호입니다.
그 렇다고 다음과 같이 보유기술을 옆으로 펼친다고 해서 달라지는 것은 없습니다. 이도 역시 1차 정규화된 테이블이 아니라고 볼 수 있습니다. 의미상으로 보유기술1, 보유기술2, 보유기술3는 그냥 보유기술의 종류일 뿐입니다. 그러니 하나의 속성에 여러 개의 값을 다른 표현으로 한 것 뿐입니다.
어떤 독자분은 보유기술 속성에 속성값을 넣는데 콤마로 구분하면 어떻겠냐? 라는 생각을 가질 수도 있습니다. 만약 사원번호 1111 인 사원의 보유기술을 하나더 추가하려면 기본키가 "사원번호" 이므로 "사원번호"가 1111 인 사원이 추가되지 못하는 것을 알 수 있습니다. 즉, 다음과 같은 그림이 되어 삽입을 할 수 없는 형태가 되는 것입니다.
이 제 본격적인 정규화에 대해서 알아보겠습니다. 아래의 테이블은 각각의 학생에 대해서 각각의 속성마다 단일값을 가지고 있으므로 1차 정규화된 테이블이 입니다. 여기서 독자분들은 함수적 종속관계를 찾아보아야 할 것입니다. 여러분은 찾아낸 함수적 종속성을 바탕으로 데이터가 많이 중복되어 있고, 그 데이터의 중복으로 인한 여러가지 문제점(이상)들을 찾아내어야 합니다.
이 테이블의 함수적 종속 다이어그램의 다음과 같습니다.
함 수적 종속 다이어그램에서 보는 바와 같이 학번은 학생명과 학년을 결정하고, 학번은 학과를 결정합니다. 또한 수강코드는 담당교수와 과목명을 결정합니다. 각각의 학생은 자신이 수강신청한 과목의 성적등급을 알기 위해서 학번과 수강코드가 필요합니다. 담당교수는 학과를 결정합니다. 여기서 자칫 잘못하면 학과가 담당교수를 결정할 수 있다고 볼 수 있는데 하나의 학과에 소속된 교수는 여러명인 것이 보입니다. 즉, 지도교수가 학과를 결정하는 것이지 학과가 교수를 결정하는 것이 아닙니다.
이제 1차정규화된 테이블을 가지고 나타나는 문제점을 살펴보도록 하겠습니다. 이러한 문제점은 함수적 종속과 관련하여 찾아보아야 합니다.
이 테이블은 학번만 가지고는 어떤 과목의 성적의 등급이 얼마인지를 모릅니다. 그러므로 이 테이블의 기본키는 학번 + 수강코드입니다. 여기서 주의할 것은 수강코드라는 속성의 이름이 수강을 해야만 하는 코드가 아니라는 사실입니다. 즉, 수강할때 그 과목을 나타내는 과목의 고유번호응 나타내는 것입니다.
2차 정규화
앞 서서 삽입, 삭제, 갱신 이상들이 일어 날 수 있다는 것을 보았습니다. 1차 정규화된 테이블에서 이러한 문제점이 일어나는 원인이 무엇일까요? 원인은 바로 기본키가 아닌 각각의 속성들이 기본키에 종속적이지 않고, 부분적으로 함수 종속이 되기 때문입니다. 즉, 기본키를 제외한 모든 속성이 기본키에 함수적 종속이 아니기 때문입니다. 이러한 문제를 해결하기 위해서는 기본키에 함수 종속을 시킨 것 끼리 따로 테이블을 만들어야 합니다. 2차 정규화된 테이블은 다음과 같습니다. ( 테이블 밑은 점(...)은 생각치 않도록 하겠습니다. )
2 차 정규화의 결과로 위와 같은 3개의 테이블이 나왔습니다. 학생과 수강과목은 다:다의 관계를 맺고 있기 때문에 학생의 학번과 수강과목의 수강코드가 합쳐진 것을 기본키로 하여 학생 테이블과 수강과목 테이블을 연관지어 주고 있습니다. 사실 데이터 모델링의 초기단계부터 차근 차근 진행해 오면서 엔티티만 제대로 도출해 냈다면 이와 같은 2차 정규화 작업은 필요가 없습니다. 그러나 이와 같은 검증된 원리를 알고 있다면 애매모호 함이 없어지고, 좀더 정확한 정보를 산출하는 정보시스템이 만들어 질 수 있는 것입니다.
학생 테이블과 수강과목 테이블에 학과라는 속성이 중복되어 존재하는 것이 보입니다. 이것은 어떤 다른 엔티티 집합이 더 존재한다는 것을 의미합니다. 즉, "학과" 엔티티가 "학생"과 "수강과목"과 관계를 맺고 있다는 것입니다. 위의 테이블을 볼 때 학과와 관련된 엔티티와 학생, 수강과목은 1:다의 관계를 맺고 있음을 알 수 있습니다. 즉,
학과 : 학생 1 : 다 학과 : 수강과목 1 : 다
의 관계입니다. (사실 더많은 객관적인 업무규칙이 파악되어야 정확히 알수 있습니다.) 그러므로 속성의 이름은 학과보다는 "학과명"이라고 하는 것이 더 명확하겠지요. 그러나 이 단원에서는 다른 엔티티 집합은 생각치 않고, 이에 대한 고려는 다음 단원에서 하겠습니다. 단지 이것은 정규화를 위한 예제라는 것을 염두해 두시기 바랍니다.
이제는 어느정도 속성들이 자신이 있어야 할 곳에 배치된 것으로 보입니다. 그러나 이러한 2차 정규화 테이블에도 이상들이 존재합니다. 이러한이상들을 살펴보도록 하겠습니다.
2 차 정규화된 테이블에서 이상이 일어나는 이유는 기본키가 아닌 다른 속성들 간에 함수적 종속이 일어나기 때문입니다. 이렇게기본키가 아닌 속성들끼리의 종속성을 가지는 것은 이행 종속(Transitive Function Dependency) 라고 합니다. 이러한 개념으로 위의 테이블에서 일어날 수 있는 문제점을 찾아보록 하겠습니다. 먼저 문제의 이행 종속이 일어나고 있는 테이블을 추려내야 합니다. 앞서서 그려본 함수적 종속 다이어그램에서와 같이 이행 종속이 일어나고 있는 테이블은 수강과목 테이블입니다.
삽입이상: 각 과목을 담당하는 교수가 특정 학과에 속한다는 사실을 삽입하려 할 때 과목이 존재하지 않는다면 이 사실을 삽입할 수 없습니다. 즉, 각각의 행을 구분할 수 있는 대표성을 지닌 속성(기본키)가 존재하지 않으므로 삽입이 불가능하다는 것입니다. 기본키는 수강과목 테이블에서 반드시 들어가야만 하는 것인데 이를 무시한채 다른 속성값을 삽입하려 한 것이 문제입니다.
삭제이상: 만약 해당 학과의 커리큘럼이 바뀌어 오상훈 교수가 담당하고 있는 과목인 "자료구조"라 는 과목이 없어진다면 오상훈 교수가 정보통신공학과에 소속된다는 사실도 없어지게 됩니다. 오상훈 교수가 정보통신공학과에 소속된다는 사실은 이행종속이 일어나고 있다는 것이며, 역시 2차 정규화된 테이블에서 일어나는 삭제이상도 이행 종속때문이라는 것을 알 수 있습니다.
갱신이상: 만약 박덕규 교수의 소속 학과가 정보통신에서 다른 학과로 변경된다면 박덕규 교수에 해당되는 학과에 대한 속성값을 모두 변경시켜 주어야 합니다. 역시 이행종속이 일어나서 일어나는 이상현상입니다.
3차 정규화
2 차 정규화된 테이블에서 이행 종속에 의해서 여러 가지 이상현상이 발생되는 것을 보았습니다. 이러한 여러 이상현상을 제거하려면 어떻게 해야 할까요? 당연히 이상현상의 원인이 되었던 이행종속을 없애면 됩니다. 어떻게 없애야 할까요? 당연히 이행종속을 일으키는 속성들을 묶어서 그룹지어 주면 문제는 해결됩니다.
이 렇게 이행 종속성을 제거한 테이블은 3차 정규화된 테이블입니다. 만약 독자분들 중에 여기까지 대충 읽어 보신분들은 아마도 정규화란 것이 테이블을 쪼개는 것이구나 라고 생각하시는 분들도 계실겁니다. 그러나 테이블을 쪼갠다는 개념을 갖지 말고, 좀더 세부적으로 관련성이 많은 것끼리 새로운 그룹을 만드는 개념으로 정규화를 생각하셔야 합니다.
<쉬어가기>
자존심... 여 러분은 느껴보셨는지요? 공대인이 마음이 닫혀있다는 것을... 얼마전 웹상에서 알게된 친구가 저에게 메신저로 호출을 하더군요. 그래서 왜 그러느냐고 했더니 지금 큰일났다고 하더군요. 다시 왜 그러냐고 물었더니 지금 자기가 하고 있는 프로젝트가 원래 D사 의 프로젝트인데 하청으로 받아서 하고 있는데, D사 사람이 와서 DB설계 개판(?)으로 했다고 하면서 엄청 깨졌다고 하더군요. 그러더니이거 DB 설계 다시해서 그쪽 사람과 협상해야 한다고 하소연을 했습니다. 그래서 한번 보자고 했습니다. ㅡㅡ;;
저 는 그 DB설계 해논 것을 보고 이게 도대체 머냐? 그럴만 하다 라고 했습니다. 그랬더니 자기자신도 모르는 상태에서 했기 때문에 그럴만 하다라는 것을 인정하면서도 너무나도 화가 난다고 하는 것이 였습니다. 왜 화가 나는 것일까요? 자신이 해논 것에 대한 쓸 때 없는 자존심 때문일까요?
이 상스럽게 이쪽 분야에서 일하는 사람이나 공부하는 사람들은 지는 것을 싫어합니다. 사실 게임도 아닌데 많은 사람들이 자신이 제시한 솔루션이 가장 옳다라고 우겨서(?) 이기고자하는 경향이 있습니다.(물론 필자도 그런 경향이 매우 짙게 나타납니다. 모르는 것도 전에 알던 지식을 이용해서 논리적으로 엮어서 아는 척하는 합니다. ㅡㅡ;;) 정보기술분야는 너무나도 빨리 발전하고 있습니다. 거의 대부분의 사람이 따라가기 바쁘지요. 물론 필자도 따라가기가 너무 힘듭니다. 그래서 매일 꾀죄죄한 모습으로 학교에서 중국음식에 길들여지면서 고생하는 이유일지도 모르겠습니다. 다음 그림을
여러분은 마음을 열고 다른 사람의 것을 받아들일 수 있어야합니다. 너무나도 빨리 발전하고 있는 기술을 따라가는데 가장 빠른 지름길은 사람과 사람이 나누는 Communication 일것입니다.
보이스/코드 정규화
3 차 정규화도 여러가지 이상이 존재합니다. 그렇다면 이상이 발생하지 않는 정규화 과정은 어떤거냐고 의문을 가지는 분도 있을 겁니다. 이상이 발생하지 않는 정규화는 키/도메인 정규화입니다. 이것은 증명은 되었으나, 키/도메인 정규화 테이블을 만드는 구체적인 방법을 발견하지 못했기 때문에 실무에서 직관적으로 사용되는 방법이기도 합니다. 그러나 보통 실무에서는 3차 정규화과정이나 다음에 할 보이스/코드 정규화까지 합니다. 그 이유는 일반적으로 4차 정규화나 5차 정규화 과정을 거쳐야 하는 상황은 거의 발생하지 않기 때문입니다. 이 책에서는 보이스/코드 정규화 과정까지만 언급하겠습니다. 만약 보이스/코드 정규화 과정을 거쳤으나 사용자가 원하는 작업을 수행할 때 이상이 발생한다면 4차 정규화 과정을 거쳐야 할 것입니다. 4차, 5차 정규화는 다른 책을 참고하셔야 할 것입니다.
이제 위의 3차 정규화를 거친 테이블에 대한 이상현상이 발생하는 원인을 분석하고 보이스/코드 정규화에 대해서 언급하도록 하겠습니다.
3 차 정규화 과정을 거치 테이블에서 이상현상을 발생시키는 원인은 후보키들이 중첩되어 있다는 것 때문입니다. 후보키는 기본키가 될 수 있는 자격이 있는 속성 또는 속성들입니다. 즉, 하나의 릴레이션에 여러 개의 후보키가 존재하는데 하나 또는 여러 개의 속성이 중첩되어서 후보키될 때 이상현상이 발생할 수 있다는 것입니다. 보이스/코드 정규화 과정은 바로 이러한 문제점을 해결하는 것입니다. 이러한 의미에서 볼 때 보이스/코드 정규형은 엄격한 3차 정규형이라고도 합니다.
보 이스/코드 정규형은 릴레이션의 모든 결정자가 후보키이면 보이스/코드 정규형이라고 보는 것입니다. 결정자라는 개념은 어떤 속성을 함수적으로 완전히 종속시키는 속성을 의미합니다. 만약 다음의 업무 규칙이 존재하는 테이블이 있다고 가정 한다면
-. 하나의 과목을 여러 교수가 담당할 수 있다. -. 각 교수는 하나의 과목만을 담당한다. -. 각각의 학생은 같은 과목명을 가진 다른 과목을 수강하지 못한다.
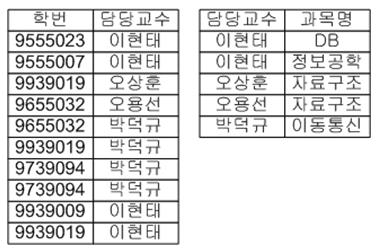
앞서서 언급한 3차 정규화의 문제점인 후보키의 일부가 되는 속성인 "학번"이 중첩되어 있는 것이 보입니다. 즉, 수강_교수 릴레이션의 후보키는 "학번 + 과목명" , "학번 + 담당교수" 입니다. 이 후보키중 "학번 + 과목명"을 기본키라고 가정하겠습니다. 함수 종속 다이어그램에서 보는 바와 같이 "학번 + 과목명"은 "담당교수"를 결정하고, "담당교수"는 "과목명"을 결정합니다. 이런 구조를 가지고 있는 릴레이션의 문제점을 파악해 보도록 하겠습니다.
삽입이상: 만약 이현태 교수도 자료구조를 담당하게 되었다면 수강신청을 한 학생이 있어야만 이와 같은 사실을 입력할 수 있습니다. 만약 "담당교수"의 의마가 해당 과목을 담당하고, 또한 그 학생에 대한 생활지도 등의 "지도"를 할 수 있다면(여기서는 담당과목을 수강하지 않은 학생도 지도할 수 있다는 가정), 과목을 수강하지 않은 학생은 지도교수가 누구인지 결정을 할 수 없게 됩니다.
삭제이상: 학번이 "9655032" 인 학생이 자료구조의 수강 취소를 한다면 오용선 교수가 자료구조를 담당하고 있다는 사실도 함께 삭제됩니다. 이 뿐만 아니라 다른 과목들도 마찬가지로 수강하는 학생이 수강을 취소한다면 과목에 대한 담당교수도 같이 삭제되므로 이상현상이 일어납니다. 만약 다른 수강 신청자가 있다면 이와 같은 사실은 같이 삭제되지 않으나 현재 상황으로 볼 때 어떤 교수가 어떤 과목을 담당하고 있는지를 나타내는 것이 한 개의 투플(행)뿐이기 때문에 이러한 문제를 해결되어야 합니다.
갱신이상: 만약 이현태 교수가 "DB" 에서 "네트웍 프로그래밍"으로 담당과목이 바뀌었다면 3개의 투플(행)을 모두 변경해주어야 합니다.
이러한 문제점은 보이스/코드 정규화 과정을 거치면 해결되는 문제입니다. 즉, "모든 결정자가 후보키" 가 되게 하면 되는 것입니다. 다음은 보이스/코드 정규화의 결과입니다.
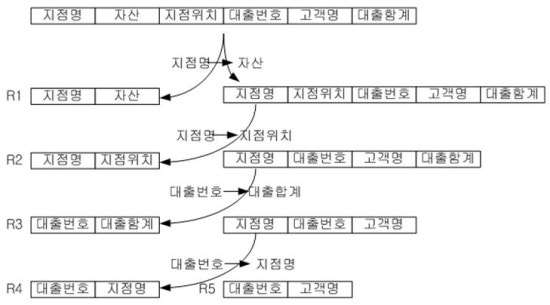
이 제 여러분은 1차 정규화에서 3차 정규화 까지를 종합적으로 살펴볼 필요가 있습니다. 즉, 이러한 원리만 알고 있다면 바로 3차 정규화 또는 보이스/코드 정규화까지 직접 도출이 가능합니다. 직접 도출하는 예를 들어 보겠습니다. 다음과 같은 스키마가 존재하다고 가정하겠습니다.
대출 (대출번호, 고객명, 지점명, 지점위치, 자산, 대출합계)
이 스카마는 어떤 은행은 대출에 관련된 스키마입니다. 이 스키마를 가지고 함수적 종속만 파악한다면 나머지 보이스/코드 정규형을 도출하는 과정은 간단합니다. 다음은 이 스키마에 대한 함수적 종속을 나타내는 것입니다.
<함수적 종속> 지점명 자산 지정명 지점위치 대출번호 대출합계 대출번호 지점명
도 출한 R1, R2, R3, R4, R5는 모두 보이스/코드 정규형을 만족합니다. 각각의릴레이션의 모든 결정자가 후보키입니다. 그러나 이렇게 너무 불필요한 정규화는 결과적으로 성능을 떨어뜨릴 수 있습니다. 그러므로 다음과 같은 통합작업을 거쳐야 합니다.
결 과적으로 R1(지점명, 자산), R2(지점명, 지점위치), R3(대출번호, 대출합계), R4(대출번호, 지점명), R5(대출번호, 고객명)으로 일단은 테이블을 최대한 분해하였습니다. 그러나 R1과 R2는 기본키가 같으므로 통합할 수 있습니다. 그러므로 R1_2 (지점명, 자산, 지점위치) 로 통합되고, R3와 R4, R5가 기본키가 같으나 R3, R4와 R5는 은행(R3, R4)과 고객(R5)으로 서로 다른 것을 나타내므로 R3와 R4는 통합되고, R5는 독립적으로 존재하게 됩니다. 즉, (R3, R4)와 R5는 표현하려는 정보가 틀리기 때문에 통합이 불가능합니다. 마지막에 나온 R5는 원래 정규화되기 전의 원래 테이블의 기본키가 됩니다. 결과적으로 다음과 같이 보이스/코드 정규화가 이루어졌습니다.
R1_2 (지점명, 자산, 지점위치) R3_4 (대출번호, 지점명, 대출합계) R5 (대출번호, 고객명)
결 과적으로 정규화라는 과정은 함수적 종속이라는 하나의 원칙으로 관련성으로 속성들을 묶어서 데이터의 중복을 없애고, 데이터의 중복에 의한 여러가지 이상현상을 없애는 유용한 도구입니다. 데이터의 중복이 최소화되는 자체는 시스템이 가장 가벼운 데이터를 가지고 처리하기 때문에 전체적인 시스템의 성능이 높아지기도 하는 것입니다.
키/도메인 정규화
' 정규화란것은 '함수적 종속'관계를 파악하는 것입니다. 이 종속관계를 파악하여 속성이 원래 갈 자리에 가게 하는 것입니다. 즉, 주제에 맞는 한 객체가 관련된 업무에 관한 속성들이 있어야 할 곳에 있게 하는 것입니다. 우리는 1차 정규화에서 보이스/코드 정규화까지 알아보았습니다. 보통 실무에서는 3차 정규화나 보이스/코드 정규화 때에 따라서는 아주 가끔씩 4차정규화를 행합니다.
그 러나 검증은 되었으나 그 방법이 찾아지지 않은 키/도메인 정규화를 이 글에서 이야기하고자 합니다. 키(key)라는 것은 객체를 유일하게 구별할 수 있는 속성중에 가장 관련된 대표적인 것을 이야기 합니다. 이 키에 함수적으로 모두 종속되고, 속성의 도메인이 맞다면 즉, 모든 제약이 키와 도메인의 정의에 따른 논리적인 결과인 것은 모두 키/도메인 정규화인 것입니다. 이 것은 완벽한 정규화입니다. 3차 정규형은 기본키에 모두 함수적 종속적인 것들로 테이블을 분리하고, 기본키가 아닌 속성들끼리의 종속성 즉, 이행종속을 일으키는 속성들을 다른 테이블로 옮기고 그 테이블에 기본키를 정의할 수 있으면 됩니다. 이와 같이 분리된 테이블은 기본키를 가지게 됩니다. 이러한 개념으로 테이블을 봤을때 데이타가 중복되어 나타나는 것들 잘 살펴보면, 왜 중복이 일어났는지 알수 있을 것입니다.
정 규화의 해법들이 키/도메인 정규화 빼고는 모두 나와있습니다. 그러나 직관적으로 바라본다면 해법이 나와 있지는 않지만 키/도메인 정규화가 더 쉽습니다. 또한 초기에 엔티티를 선정할때 우리가 시스템화 하고자하는 관련된 것들끼리 모인 즉, 엔티티를 잘 선정한다면 직관적인 관점에서 3차정규화는 충분히 할 수 있으리라 생각합니다. 그 렇다고 정규화 과정을 무시해서는 안됩니다. 이렇게 직관적으로 설계를 하면서 나갈때는 정규화는 검증도구가 되는 것입니다. 학자에 따라서 정규화는 검증도구다 또는 튜닝도구다라고 하는 의견들이 분분합니다. 그러나 정규화는 반드시 필요한 것이 틀림이 없습니다.
도 메인/키 정규화에서 중요한 단어는 제약, 키, 도메인입니다. 한가지 주의할 것은 제약에 시간의 개념을 뺏다는 것입니다. 엑기스만 뽑는다면 키와 도메인에 대한 제약을 준수시켰을때 모든 제약이 준수되는 릴레이션은 키/도메인 정규형입니다.
다 시 핵심단어 키, 도메인, 제약 이 세가지의 관점에서 살펴보겠습니다. 키라는 것은 객체들을 유일하게 구분지어 주는 속성입니다. 즉, 속성들중 대표하는 것을 말합니다. 이 속성들이 가질수 있는 값들의 범위를 정의한 것이 바로 도메인입니다. 독자들중에 아시는 분이 별로 없으시겠지만 푸리에변환 같은 것을 보면 시간 도메인에서 주파수도메인으로 주파수 도메인에서 시간 도메인으로 변환을 할 수 있습니다. 시간 도메인에서 본다면 이 값들은 절대로 변환과정을 거치지 않고는 시간이라는 단위밖에 가지지 못하는 것입니다. 실제로 주민번호를 본다면 생년월일 담에 오는 1이란 숫자는 남자밖에 가지지 못하는 숫자입니다. 이 도메인을 벗어난다면 현실에 맞지 않게 되는 것입니다. 누누히 얘기하지만 데이타베이스는 현실을 최대한 반영하는 것입니다.
정리하자면 키라는 것은 "unique + not null + 대표성" 입니다. 도메인은 앞에서 얘기한 것처럼 속성이 가질수 있는 값의 범위이고 가질수 있는 꼭 그것을 가져야만 하는 의미입니다. 이것은 현실의 제약이라고 볼수 있으며, 이러한 제약이 지켜진다면 이것은 완벽한 이상이 없는 정규형입니다. 정규화의 정리
이 제 앞에서 살펴보았던 정규화에 대해서 의미로만 따져도록 하겠습니다. 필자의 경우는 정규화 과정은 검증도구로 사용하는 편입니다. 사실 함수적 종속이란 것이 조직의 범위내에서 통용되는 의미에 따라 틀려집니다. 그러므로 모델링을 하기전 단계에서부터 정보시스템을 구축하려는 조직에서 사용되는 정보의 의미를 파악하는 것이 더 중요하다고 합니다.
3 차 정규화된 테이블을 보면 테이블마다 어떤 정보들을 나타내기 위해서 데이터 들이 뭉쳐있습니다. 즉, 각각의 속성들이 뭉쳐서 어떠한 하나의 정보(의미)를 만들어 내기 때문에 그 의미만 잘 파악한다면 앞에서 행했던 것처럼 바로 보이스/코드 정규화까지 직접 도출이 가능한 것입니다. 그냥 어떤 "의미"를 나타내기 위해서 그룹짓는 과정이라고 하기엔 너무 애매모호 합니다. 그래서 함수적 종속이란 개념을 도입하여 누구나 고개를 끄덕이게 만든 것이 정규화입니다.
독 자가 파악해야 할 것은 사용자의 정보가 무엇인지 정확하게 판단하여야 할 것입니다. 만약 사용자의 요구사항이 정확하게 파악되면, 그 요구사항을 정확히 반영하기 위해서 엔티티를 도출하고, 각각의 속성들을 배치해야 합니다. 엔티티는 속성의 집합이기도 합니다. 하나의 엔티티가 다른 엔티티와 관계를 맺고, 어떠한 정보를 만들어 낼 수 있습니다.
일반적으로 데이터 모델링은 하향식(Top-Down)의 방식으로 설계를 하고, 정규화를 통한 하향식(Bottom-up) 방식으로 검증을 하는 방법론을 사용합니다. 이제 속성을 가지고 다음 그림을 살펴보도록 하겠습니다.
제일 먼저 파악해야 할 것은 "관련성" 입니다. 릴레이션이란 것이 속성들이 어떠한 관련성에 묶여서 있는 모습입니다. 그러니 관련성이라는 의미는 매우 중요한 것입니다. 이것은 기본키와의 관련성입니다. 하나의 개체( 학생으로 하였을 경우 학번이 9555023인 학생 하나는 인스턴스입니다.)를 대표하는 것이 기본키이기 때문입니다.
두 번째는 파악해야 할 것은 속성의 도메인입니다. 각각의 속성은 가질 수 있는 값의 범위 즉, 도메인을 가지고 있습니다. 이 도메인에서 표현할 수 있는 속성값들을 대표할 수 있는 것들을 찾는 것입니다. 이 도메인도 관련된 엔티티의 범위를 가지기 때문에 관련성이라는 것은 매우 중요합니다.
의 미상으로 볼 때 학번과 학생명이 같은 객체의 다른 표현인 것을 알 수 있습니다. 그러나 한 학년에 속하는 학생이 여러명인 것을 알 수 있지만, 학년자체는 독립적으로 존재할 수 있는 즉, 엔티티가 아니라 속성이라는 것입니다. 결과적으로 이 릴레이션은 "학생" 엔티티 집합이 포함된 것입니다.
이 러한 방식으로 속성값을 살펴보면 위의 그림이 나올 수 있습니다. 그림에서 학과명과 관련된 것을 살펴보면, 일단 학번이 이름과 학년을 결정하는 것은 앞에서 체크었으므로 이 두 속성은 제외하고 학번으로만 생각해보도록 하겠습니다. 학번이 학과명을 결정하나요? 이 부분은 상당한 혼돈의 여지가 있습니다. 그러나 좀더 원천적으로 생각하면 데이터베이스 시스템을 개발하려는 도메인이 무엇인가요? 바로 "학교"입니다. 즉, 학교에는 기본적으로 "학생"과 "학과"가 존재해야 "학교"가 존재할 수 있는 것입니다. 즉, 학과와 학생은 기본엔티티 집합인 것입니다. 이렇게 "닭이 먼저냐? 달걀이 먼저냐?" 라고 따지는 상황이 온다면 이것은 기본엔티티 집합입니다. 그러므로 학과명은 "학과" 엔티티 집합의 속성입니다. 그러므로 이것은 외부키인 것입니다. 그렇다면다른 속성은 어떨까요? 당연히 다른 속성들도 따져볼 것이 못되는 것입니다. 만약 관련이 있다면 그것은 외부키로 의 기능을 하는 속성입니다.
결과적으로 이 테이블에서 도출할 수 있는 엔티티 집합은 "학생", "수강(또는 과목)", "학과", "교수" 입니다. "학생" 과 "수강" 은 다:다의 관계를 맺고 있으므로 "수강코드, 학번, 등급" 은 이 다:다의 관계를 해소한 것이 되는 것입니다.
이렇게 엔티티와 속성과 관계를 도?하는 것은 데이터 모델리의 핵심입니다. 이와 같은 기본적인 것만 확실히 파악이 된다면 정규화는 데이터 모델링의 검증의 도구와 튜닝의 도구로 써 훌륭한 역할을 할 것입니다. |
















출처: http://blog.naver.com/suchang331?Redirect=Log&logNo=150003166165
<표 1> 정규화에 대한 정리
1차 정규화 사례 1
<그림 2> 1차 정규화의 응용 1
이 사례의 특징은 주문의 PK(Primary Key)인 주문번호가 중복 속성 값을 가지기 때문에 PK를 가진 데이터베이스 테이블 생성이 불가능하다는 특징이 있다.
1차 정규화 사례 2
<그림 3> 1차 정규화의 응용 2
<그림 3>의 모델을 보면 왼쪽 모델의 일재고 엔티티 타입에는 3개월 분에 대한 장기재고 수량, 주문수량, 금액, 주문금액이 차례대로 기술되어 있다. 이렇게 되면 장기재고 관리가 4개월 이상으로 늘어날 때 모델을 변경해야 하는 치명적이 결함이 있다. 따라서 오른쪽과 같이 1차 정규화를 통해 모델을 분리함으로써 업무 변형에 따른 데이터 모델의 확장성을 확보하도록 해야 한다.
2차 정규화(주식별자에 종속적이지 않은 속성의 분리) 1차 정규화를 진행했지만 속성 중에 주식별자에 종속적이지 않고 주식별자를 구성하는 속성의 일부에 종속적인 속성인, 부분종속 속성(PARTIAL DEPENDENCY ATTRIBUTE) 을 분리하는 것이 2차 정규화(SECOND NORMALIZATION)이다. 2차 정규화는 반드시 자신의 테이블을 주식별자를 구성하는 속성이 복합 식별자일 경우에만 대상이 되고 단일 식별자일 경우에는 2차 정규화 대상이 아니다.
2차 정규화 사례
<그림 4> 2차 정규화 응용
<그림 4>의 모델은 고객번호에 종속적이지 않은 속성들을 분리하여 고객점포라는 새로운 엔티티 타입을 생성하였다. 실전 프로젝트에서는 코드 유형의 엔티티 타입들이 2차 정규화가 되지 않고 하나의 엔티티 타입으로 표현되는 경우가 많이 발견된다. 이 모델에서 함수종속 관계 표기법으로 표기하자면 고객번호 -> (고객명)으로 표시하여 별도의 엔티티 타입으로 분리할 수 있다.
3차 정규화(속성에 종속적인 속성 분리) 3차 정규화(third normalization)는 속성에 종속적인 속성을 분리하는 것이다. 즉 1차 정규화나 2차 정규화를 통해 분리된 테이블에서 속성 중 주식별자에 의해 종속적인 속성 중에서 다시 속성 간에 종속 관계가 발생되는 경우에 3차 정규화를 진행한다.
3차 정규화 실전 적용
<그림 5> 3차 정규화 응용
<그림 5>의 모델은 고객 엔티티 타입에 등록카드에 대한 정보가 포함되어 있는 모습이다. 등록카드번호가 결정자 역할을 하고 있고 등록카드사명과 등록카드유효일자가 의존자 역할을 하는 속성 간의 종속적인 속성이 발견되었으므로 3차 정규화의 대상이 되는 모델이다. 따라서 등록카드에 대한 내용에 대해 별도의 엔티티 타입을 도출한 오른쪽 모델로 만듦으로서 3차 정규화를 완성하였다. 실전 프로젝트에서는 1:1관계의 엔티티 타입이 하나로 통합이 되었거나 업무분석 과정에서 하나의 엔티티 타입에 많은 속성이 포함되어 있을 때 3차 정규화의 대상이 되는 경우가 많이 나타난다. 이 모델에서 함수종속 관계 표기법으로 표기하자면 등록카드번호 -> (등록카드사명, 등록카드유효일자)으로 표시하여 별도의 엔티티 타입으로 분리할 수 있다.
제공 : DB포탈사이트 DBguide.net [출처] 정규화(1,2,3정규화 사례)|작성자 뚜루우 |




Flexible Display Center at ASU
Development of Low Temperature a-Si Transistors, Displays and
Electronics on Flexible Substrates
SEMICON West 2009
July 16, 2009
 Flexible Display Center at ASU.pdf
Flexible Display Center at ASU.pdf

출처: http://delphi.borlandforum.com/impboard/impboard.dll?action=read&db=del_tutorial&no=43
| 객체지향을 왜 배워야 하는가? | |
| 주정섭 [jjsverylong] | 5015 읽음 2004-10-27 15:15 |
| 객체지향을 왜 배워야 하는가? "간혹 객체지향을 왜 배워야 하는가요? 배우지 않아도 개발하는데 문제가 없는데요"라고 질문하는 사람들이 있다. 사실 어찌보면 맞는 말이다. 객체지향이 대세이기 때문에 배워야 한다는 생각도 좋지 않다. 모든 개발론은 의무감 보다는 실리적인 이유를 따져서 채택해야만 한다. 그렇다면, 객체지향을 왜 배워야 하는지 따져볼 필요가 있다. 가장 중요한 이유는 개발 속도 때문이다. 객체지향이 개발 속도를 향상시킨다는 것은 이미 여러번 증명된 바 있다. 객체지향적으로 개발들면 왜 개발 속도가 빨라질까? 그 이유들을 알아보자. 첫번째로 전면부 코드가 간략화 진다. 객체지향으로 개발하면 상당수의 코드는 뒤로 사라지고, 전면부 코드는 매우 단순해 진다. 뒤로 사라진 코드는 라이브러리리 코드인데, 델파이로 비유하자면, 콤포넌트들과 같다. 델 개발자들이 콤보박스를 사용하기 위해서, TComboBox Class의 모든 소스를 이해해야할 필요가 있는가? 당연히 없다. 델 개발자들은 TComboBox의 사용방법만 알면 되지, 그 모든 소스를 암기하거나 매번 볼 필요가 없다. 그렇다면 내가 만든 코드에도 TComboBox처럼 한번 만들면, 다시 볼일이 없는 라이브러리 성격의 코드가 있기 마련이고, 이런 코드들을 덜어내서 다음에 봐야할 코드량을 줄여야 한다. 사실 어플 코드와 라이브러리 코드의 분리는 매우 중요한 개념이고 이를 어떻게 분리해야하는지 자세한 내용은 이번 세미나로 미루자. 그런데, 중요한 사실은 화면 배경 처리 코드와 거래처의 금액 합계 처리 코드가 한 곳에 있으면 안된다는 것이다. 이는 후일 유지보수를 엄청나게 힘들게 할 수 있다. 두번째 객체지향의 장점은, 설계 방식이 유동적이 된다는 것이다. 처음 설계대로 만들어지는 프로그램은 없다. 왜냐하면 사용자는 프로그램을 모르기 때문에 자신의 요구사항이 어떤 것인지 프로그래머에게 설명을 잘 못하고, 프로그래머는 업무를 모르기 때문에 사용자의 요구사항을 이해하지 못한다. 이러한 관점 차이를 극복하는 방법은, 빠른 시간내에 대략 동작하는 프로그램을 만든 다음, 사용자에게 이런 기능을 원하냐고 확인해 보는 것이다. 빨리 개발하여 확인하고 기능을 수정하고 추가하는 것이, 객체지향이 잘된 프로그램이 비교적 쉬운 이유는, 객체지향 방식에서는 부품 조립 방식으로 프로그램을 만들기 때문이다. 특정 부품이 안맞으면 다른 부품으로 갈아치우듯이 개발한다는 것이다. 세번째 객체지향의 좋은 점은 유지보수가 편해진다는 것이다. 과거 절차지향적 방식에서는 전역변수가 난무하고, 이 전역변수를 사용하는 전역함수간의 관계와 원칙을 개발자들이 일일이 암기해서 해야 했다. 그러나 객체지향에서는 전역 변수를 완전히 없애 버릴 수 있고, 전역변수와 그 변수를 사용하는 전역함수간에 어떤 관계가 있는지 확연히 문법적으로 표시할 수 있다. 다시 말해서, 개발론 중에서 코드 자체가 도큐멘트가 되도록 하란 말이 있는데, 객체지향에서는 클래스란 개념때문에 이것이 훨씬 쉽다는 것이다. 네번째로, 절차지향 방식에 비해서 객체지향 방식은 팀작업에서 훨씬 유리하다. 절차지향 방식에서의 팀작업은 만들 함수를 팀원들이 분담하는 방식인데 비해서, 객체지향에서는 만들 클래스를 팀원들이 보통 분담하게 된다. 이 때문에 진행 방식에서 두 방식은 차이점이 발생하는데, 절차지향에서는 처리 단계를 중시하지만, 객체지향에서는 필요한 프로그램 부품이 뭔가가 중심이 되므로, 월등히 분업이 쉽다. 다섯번째로 객체지향에서는 쪼잔한 버그들로 부터 벗어날 수 있기 때문에, 좀더 중요한 부분의 코딩에 몰두할 수 있게 된다는 것이다. 의외로, 많은 개발자들이 쪼잔한 버그들을 가볍게 본다. 가랑비에 옷 젖는다란 속담이 있듯이, 쪼잔한 버그들이 떼거리로 나타나게 되면 자칫 프라젝트 전체를 포기해야할 지경에 까지 이를 수 있다. 엄청나게 중대한 버그는 차라리 고치기 쉬울 수도 있다. 왜냐면 이런 중대한 버그들은 어떤 경우 그 버그가 재현되는지, 어디를 고쳐야 하는지를 잘 알 수 있기 때문이다. 그런데 쪼잔한 버그들이 떼거리로 발생하면, 그 버그가 언제 발생하는지 판단이 어렵게 된다. 최악의 경우는 쪼잔한 버그들이 뭉쳐서 새로운 버그를 만드는, 즉 버그들이 합성되어 새로운 희안한 버그를 만드는 경우다. 이런 경우, 정말 고치기 힘든 버그가 된다. 고치고서도 해결되었는지 안되었는지 긴가민가한 버그가 된다. 이 쪼잔한 버그들 때문에, 상당수의 개발자들이 날밤 새우는 경우가 허다하다. [맺음말] 최근 몇몇 다른 개발자들의 소스를 받아서본 결과, 이상한 방식으로 코딩을 해놓고 이를 객체지향이라고 우기는 경우가 있었다. 객체지향에는 여러 방식이 있긴 하지만, 제대로 객체지향을 적용했다면, 코딩 체계가 더욱 단순화되어야 하며, 전면부 코드가 매우 간결해 져야 한다. 이전 코드 방식에 비해서 어떤 면에서도 간결화되지 못했다면 뭔가 잘못된 것이다. 만일 이전 코드에 비해서 코딩 절차가 더 복잡해 졌거나, 전면부 코딩량이 엄청 늘어 났다면 이는 최악의 객체지향적 재난이다. 사실 객체지향을 이해하기는 쉽지 않다. 더우기 델파이에 관한 책중에서 이에 대한 체계적인 책은 정말 찾기 힘들다. 많은 델 개발자들이 델파이 팁이나, 델파이 문법 혹은 콤포넌트 사용법에 대해서 지나치게 치중하는 면이 없잖아 있다. 이런 지식도 중요하긴 하지만, 더욱 중요한 것은 올바른 코딩 습관을 몸에 터득하는 것이다. 올바른 코딩 습관을 터득해야만, 개발 속도가 빨라지고, 따라서 납기일내에 프로그램 개발이라는 중요한 약속을 어기지 않게 되고, 그래야만, 사용자는 기꺼이 돈을 지불할 것이기 때문이다. 객체지향과 올바른 코딩 습관을 익히는 가장 좋은 방법은 많은 책을 보고 연구하면서 응용해보는 것이다. 그러나, 단순히 책만보고 이론만 연구해서는 별로 소득이 없을 수도 있다. 객체지향에 익숙한 다른 개발자들의 소스를 뒤져보면서 실전에서 응용해보는 습관을 길러야 한다. 코드로 구체화되지 못하는 개발론은 말짱 헛소리기 때문이다. 이번 세미나가 객체지향의 실전 응용 방법을 여러분들에게 전달하는데 많은 도움이 되기를 바라면서, 마지막 결론을 다음과 같이 내리고 싶다. 객체지향은 델파이 뿐만 현존하는 모든 언어에서도 통용되는 개념이다. 다시 말해서 이 지식은 일회성이 아닌 장기적 이용가치가 있는 실질적인 기술이다. http://cafe.daum.net/delphinegong 주정섭의 델파이 강좌. |
출처: http://www.delmadang.com/community/bbs_view.asp?bbsNo=3&bbsCat=42&indx=196518&keyword1=TAction을&keyword2=활용하자
주정섭
(손님)
2004-06-24 오후 11:31:38
카테고리:팁
3105회 조회
TAction을 활용하자.
주위 사람들로부터 델파이 소스를 받아서 분석하다 보면, 델파이의 막강한 기능을 너무 무시(?)한 코드가 많다. 심지어 어떤 사람들로부터 비주얼 베이직에 비해서 델파이는 코딩량이 많기 때문에 생산성이 떨어진다는 이야기를 들은 적도 있다.
여러분들은 어떻게 생각하는가? 델파이는 정말 비베에 비해서 코딩량이 많은 개발툴이라고 생각하는가? 델파이는 노가다 코딩이 많은 개발툴이라고 생각하는가? 나의 경험에 의하면 현존하는 개발툴치고 델파이만큼 코딩 생산성이 뛰어난 언어는 지극히 드물다는 것이다. 비주얼 C++, 비주얼 베이직, 파워빌더, 모두들 델파이만큼의 생산성은 지원하지 못한다. C#은 이론적 언어 측면으로만 본다면 생산성이 매우 뛰어날 것 같으나, 현업에서의 실질적 생산성 측면에서는 아직은 좀더 많이 기다려봐야할 툴 같다.
문제는 상당수의 많은 델파이 개발자들이 너무 심한 노가다 코딩을 하고 있고, 그로 인해서 델파이의 뛰어난 생산성을 스스로 저버리는 실수를 범하고 있다는 것이다. 델파이는 다른 어떤 언어보다도 대부분의 경우 코딩을 매우 간략하게 할 수 있다. 파워 빌더의 경우 그 희안한 데이타 윈도우란 기능 때문에, 리포팅에서는 타 개발툴을 능가하지만, 순수 코딩적 측면에서는 결코 델파이를 능가할 수 없다. 왜냐하면 델파이는 오브젝트 파스칼이 객체지향을 거의 완벽하게 지원하며, VCL이라는 막강한 클래스 라이브러리를 가지고 있기 때문이다.
델파이 예찬론은 그만하고, 델파이의 막강한 기능 중에서, 의외로 잘 사용하지 않는 기능 중 하나인 TAction 콤포넌트에 대해서 논해 보려 한다. 많은 델파이 개발자들이 이 막강한 콤포넌트를 의외로 잘 사용하지 않는 것 같기 때문이다.
디자인 패턴을 배워 봤고 TAction을 사용해본 사람이라면, 델파이의 TAction 클래스는 Command 패턴을 적용한 것이라는 것을 잘 알 것이다. 사실 델파이 VCL 내부에는 여러 디자인 패턴들이 적용되어 있다. 디자인 패턴은 매우 오래된 개발방법론이며, 일종의 클래스 설계 정석 방법론 같은 것이므로, 볼랜드 델파이 개발자들이 당연히 이런 지식을 적용하여 델파이를 개발했다.
비주얼 C++는 ON_UPDATE_COMMND라는 요상한 매크로로 TAction과 비슷한 기능을 지원하지만, 델파이의 TAction보다는 기능이 정말로 미약하다. 어찌 일개 매크로가 객체지향적으로 설계된 TAction을 능가할 수 있겠는가? 어쨋든 TAction은 정말 기가 막힌 Non Visual 콤포넌트다. C#을 공부하면서 델파이의 TAction과 동일한 역할을 가진 클래스가 있는지 살펴 보았지만, 유감스럽게도 C#에는 이런 기능을 가진 클래스가 존재하지 않았다. 한때 델파이 설계자였던 앤델스 헤이즐버그가 TAction과 유사한 클래스를 닷넷 프레임웍에는 왜 포함하지 않았는지 참으로 납득하기 힘들다.
이론은 그만하고 TAction을 대체 어디에 사용하는지 알아보자. TAction 은 다음 세가지 핵심적 기능을 가진다.
1. 여러 UI(User Interface) 요소에 대해서 동일한 동작(기능)을 부여하고, 외향을 동일하게 하고 싶을 때.
2. 특정 UI 요소의 활성/비활성화(Enable/Disable)을 자동화하고 싶을 때.
3. 매우 복잡한 동작을 프라젝트 전반에 걸쳐 체계적으로 관리하고 싶을 때
이중 3항은 설명이 무지 어려우므로, 후일 시간이 나거나 다른 고수가 해줄 것으로 믿고, 1,2항의 기능에 대해서만 논해 보자.
이 강좌에 첨부한 예제는 다음과 같은 기능을 하는 프로그램이다.
[프로그램 기능]
1. 두개의 입력박스(TEdit)는 오로지 [정수]만을 입력 받는다.
2. 합계산 버튼을 누르면 하단 텍스트박스에 두 입력박스를 정수화하여 합한 값을 보여준다.
3. 값지우기 버튼을 클릭하면 두 입력박스의 내용을 지운다(Clear).
4. 메인메뉴에는 합계산과 값지우기 버튼과 동일한 역할을 하는 메뉴항목이 존재해야 한다. 즉 메뉴로던, 버튼으로든 동일한 기능 선택이 가능해야 함.
예제를 실행해보면 아주 간단한 프로그램이기 때문에 위 글 내용을 충분히 이해할 것이다. 그런데 이런 프로그램을 만들려면 중요한 UI 구성 요건이 필요하다.
[프로그램의 UI(User Interface) 제한 조건]
1. 두 입력박스에 모두 정수값 형태의 문자열이 입력된 상태에서만 합계산 버튼이 활성화되어야 한다. 합계산 메뉴 또한 마찬가지다.
2. 값지우기 버튼은 두 입력박스 중 어느 하나라도 입력 내용이 있을 때만 활성화 된다. 즉 두 입력박스 모두 빈상태라면 값지우기 버튼은 비활성화 되어야 한다. 값지우기 메뉴 항목도 마찬가지다.
만일 TAction을 사용하지 않았다면 이 프로그램에는 메뉴와 버튼의 활성/비활성화 처리를 위해서, 엄청나게도 많은 이벤트 메서드들을 만들어야 할 것이다. 그러나 TAction을 사용함으로써 단 몇개의 이벤트로만 해결할 수 있다.
예제 내용을 정리해보면..
1. 예제에서 TAction 콤포넌트들은 TActionList에 들어 있다. TActionList는 Action 콤포넌트들의 컨테이너(저장소) 역할을 한다. TAction 콤포넌트는 TActionList 콤포넌트 안에서 생성할 수 있다.
2. 메뉴와 버튼은 이벤트 메서서드를 속성창으로 만들지 않았고, Caption, Enabled 속성을 일일이 수동으로 지정하지도 않았다. 메뉴와 버튼의 Action 속성에 자신이 행해야 할 Action을 할당했을 뿐이다. 이로 인해서 연결된 Action 콤포넌트의 기능이 그대로 메뉴와 버튼에 전이된다. 예를 들면, 합계산 메뉴의 Caption이나 OnClick 이벤트는 actCalc를 Action 속성에 연결한 것만으로 자동 지정된다는 것이다. 합계산 버튼도 이런식으로 actCalc에 연결했다.
3. Action 콤포넌트의 OnExecute 이벤트는, 그 액션의 주된 역할인 작업 사항(할일들)을 기술하는 이벤트 메서드이다. 일반적으로 버트이나 메뉴의 OnClick 이벤트와 거의 비슷한 역할을 한다.
4. Action 콤포넌트의 OnUpdate 이벤트는, 그 Action 콤포넌트가 언제 활성/비활성화될지를 기술하는 코드가 들어간다. 이 이벤트 메서든 Idle 타임에 주기적으로 호출되고, 이로 인해서 그 액션에 연결된 모든 Control은 자동으로 활성/비활성화 된다.
결론인즉,
1. 복잡한 UI에서 특정 콘트롤을 활성/비활성화하는 로직이 복잡하다면 TAction을 사용하라.
2. 여러 콘트롤이 동일 동작을 수행해야 한다면, 역시 Action을 사용하라.
델파이 폼 코딩에서 중요한 사항 중 하나가 이벤트 메서드를 최대한 줄이라는 것이다. 그래야만 후일 소스 분석시 여러모로 편리하기 때문이다. TAction은 이런 이벤트 줄이기에 지대한 공헌을 할 수 있고, 코드를 한곳으로 모으는 역할도 한다.
그러나, TAction에는 이보다 더 황당무게하고 재밌는 기능들이 많다. TAction은 거의 콤포넌트같은 역할을 하기 때문에 새로운 TAction타입을 정의할 수도 있다. 이에 관한 다른 고수의 추가글을 기대해 본다.
덧글 : 6 개
김시준 (non) 삭제를 위한 암호를 넣어 주세요
저는 주로 펑션키를 사용할 때 주로 이용을 했었는데.. 많은 도움이 됐습니다.. 2004-06-25
민성기 (non) 삭제를 위한 암호를 넣어 주세요
좋은 글 항상 감사드리고 있습니다~ ^^; 2004-06-26
신동훈 (non) 삭제를 위한 암호를 넣어 주세요
흠 액션은 상당히 좋은 기능입니다 예전에 메신져 만들때 연계되는 UI때문에 코드로 하기 귀찮아서 액션리스트로 해결해버린적이 있습니다. 코드가독성도좋고 괜찮더군요 2004-06-28
신동훈 (non) 삭제를 위한 암호를 넣어 주세요
그리고 액션 리스트 뿐만아니라 액션메니져와 기타 에디셔널 탭에이는 액션관련 컴포넌트도 상당히 괜찮습니다 2004-06-28
전희원 (non) 삭제를 위한 암호를 넣어 주세요
정말 많은 도움이 되었습니다. 2004-07-21
블루판 (myselfcall) 삭제를 위한 암호를 넣어 주세요
소스코드에 형 변환에러가 있더군요
텍스트박스에 임의의값을 넣고 실행하시면됩니다. 2008-02-04 오후 2:48:07
주정섭
(손님)
2004-06-24 오후 11:31:38
카테고리:팁
3105회 조회
TAction을 활용하자.
주위 사람들로부터 델파이 소스를 받아서 분석하다 보면, 델파이의 막강한 기능을 너무 무시(?)한 코드가 많다. 심지어 어떤 사람들로부터 비주얼 베이직에 비해서 델파이는 코딩량이 많기 때문에 생산성이 떨어진다는 이야기를 들은 적도 있다.
여러분들은 어떻게 생각하는가? 델파이는 정말 비베에 비해서 코딩량이 많은 개발툴이라고 생각하는가? 델파이는 노가다 코딩이 많은 개발툴이라고 생각하는가? 나의 경험에 의하면 현존하는 개발툴치고 델파이만큼 코딩 생산성이 뛰어난 언어는 지극히 드물다는 것이다. 비주얼 C++, 비주얼 베이직, 파워빌더, 모두들 델파이만큼의 생산성은 지원하지 못한다. C#은 이론적 언어 측면으로만 본다면 생산성이 매우 뛰어날 것 같으나, 현업에서의 실질적 생산성 측면에서는 아직은 좀더 많이 기다려봐야할 툴 같다.
문제는 상당수의 많은 델파이 개발자들이 너무 심한 노가다 코딩을 하고 있고, 그로 인해서 델파이의 뛰어난 생산성을 스스로 저버리는 실수를 범하고 있다는 것이다. 델파이는 다른 어떤 언어보다도 대부분의 경우 코딩을 매우 간략하게 할 수 있다. 파워 빌더의 경우 그 희안한 데이타 윈도우란 기능 때문에, 리포팅에서는 타 개발툴을 능가하지만, 순수 코딩적 측면에서는 결코 델파이를 능가할 수 없다. 왜냐하면 델파이는 오브젝트 파스칼이 객체지향을 거의 완벽하게 지원하며, VCL이라는 막강한 클래스 라이브러리를 가지고 있기 때문이다.
델파이 예찬론은 그만하고, 델파이의 막강한 기능 중에서, 의외로 잘 사용하지 않는 기능 중 하나인 TAction 콤포넌트에 대해서 논해 보려 한다. 많은 델파이 개발자들이 이 막강한 콤포넌트를 의외로 잘 사용하지 않는 것 같기 때문이다.
디자인 패턴을 배워 봤고 TAction을 사용해본 사람이라면, 델파이의 TAction 클래스는 Command 패턴을 적용한 것이라는 것을 잘 알 것이다. 사실 델파이 VCL 내부에는 여러 디자인 패턴들이 적용되어 있다. 디자인 패턴은 매우 오래된 개발방법론이며, 일종의 클래스 설계 정석 방법론 같은 것이므로, 볼랜드 델파이 개발자들이 당연히 이런 지식을 적용하여 델파이를 개발했다.
비주얼 C++는 ON_UPDATE_COMMND라는 요상한 매크로로 TAction과 비슷한 기능을 지원하지만, 델파이의 TAction보다는 기능이 정말로 미약하다. 어찌 일개 매크로가 객체지향적으로 설계된 TAction을 능가할 수 있겠는가? 어쨋든 TAction은 정말 기가 막힌 Non Visual 콤포넌트다. C#을 공부하면서 델파이의 TAction과 동일한 역할을 가진 클래스가 있는지 살펴 보았지만, 유감스럽게도 C#에는 이런 기능을 가진 클래스가 존재하지 않았다. 한때 델파이 설계자였던 앤델스 헤이즐버그가 TAction과 유사한 클래스를 닷넷 프레임웍에는 왜 포함하지 않았는지 참으로 납득하기 힘들다.
이론은 그만하고 TAction을 대체 어디에 사용하는지 알아보자. TAction 은 다음 세가지 핵심적 기능을 가진다.
1. 여러 UI(User Interface) 요소에 대해서 동일한 동작(기능)을 부여하고, 외향을 동일하게 하고 싶을 때.
2. 특정 UI 요소의 활성/비활성화(Enable/Disable)을 자동화하고 싶을 때.
3. 매우 복잡한 동작을 프라젝트 전반에 걸쳐 체계적으로 관리하고 싶을 때
이중 3항은 설명이 무지 어려우므로, 후일 시간이 나거나 다른 고수가 해줄 것으로 믿고, 1,2항의 기능에 대해서만 논해 보자.
이 강좌에 첨부한 예제는 다음과 같은 기능을 하는 프로그램이다.
[프로그램 기능]
1. 두개의 입력박스(TEdit)는 오로지 [정수]만을 입력 받는다.
2. 합계산 버튼을 누르면 하단 텍스트박스에 두 입력박스를 정수화하여 합한 값을 보여준다.
3. 값지우기 버튼을 클릭하면 두 입력박스의 내용을 지운다(Clear).
4. 메인메뉴에는 합계산과 값지우기 버튼과 동일한 역할을 하는 메뉴항목이 존재해야 한다. 즉 메뉴로던, 버튼으로든 동일한 기능 선택이 가능해야 함.
예제를 실행해보면 아주 간단한 프로그램이기 때문에 위 글 내용을 충분히 이해할 것이다. 그런데 이런 프로그램을 만들려면 중요한 UI 구성 요건이 필요하다.
[프로그램의 UI(User Interface) 제한 조건]
1. 두 입력박스에 모두 정수값 형태의 문자열이 입력된 상태에서만 합계산 버튼이 활성화되어야 한다. 합계산 메뉴 또한 마찬가지다.
2. 값지우기 버튼은 두 입력박스 중 어느 하나라도 입력 내용이 있을 때만 활성화 된다. 즉 두 입력박스 모두 빈상태라면 값지우기 버튼은 비활성화 되어야 한다. 값지우기 메뉴 항목도 마찬가지다.
만일 TAction을 사용하지 않았다면 이 프로그램에는 메뉴와 버튼의 활성/비활성화 처리를 위해서, 엄청나게도 많은 이벤트 메서드들을 만들어야 할 것이다. 그러나 TAction을 사용함으로써 단 몇개의 이벤트로만 해결할 수 있다.
예제 내용을 정리해보면..
1. 예제에서 TAction 콤포넌트들은 TActionList에 들어 있다. TActionList는 Action 콤포넌트들의 컨테이너(저장소) 역할을 한다. TAction 콤포넌트는 TActionList 콤포넌트 안에서 생성할 수 있다.
2. 메뉴와 버튼은 이벤트 메서서드를 속성창으로 만들지 않았고, Caption, Enabled 속성을 일일이 수동으로 지정하지도 않았다. 메뉴와 버튼의 Action 속성에 자신이 행해야 할 Action을 할당했을 뿐이다. 이로 인해서 연결된 Action 콤포넌트의 기능이 그대로 메뉴와 버튼에 전이된다. 예를 들면, 합계산 메뉴의 Caption이나 OnClick 이벤트는 actCalc를 Action 속성에 연결한 것만으로 자동 지정된다는 것이다. 합계산 버튼도 이런식으로 actCalc에 연결했다.
3. Action 콤포넌트의 OnExecute 이벤트는, 그 액션의 주된 역할인 작업 사항(할일들)을 기술하는 이벤트 메서드이다. 일반적으로 버트이나 메뉴의 OnClick 이벤트와 거의 비슷한 역할을 한다.
4. Action 콤포넌트의 OnUpdate 이벤트는, 그 Action 콤포넌트가 언제 활성/비활성화될지를 기술하는 코드가 들어간다. 이 이벤트 메서든 Idle 타임에 주기적으로 호출되고, 이로 인해서 그 액션에 연결된 모든 Control은 자동으로 활성/비활성화 된다.
결론인즉,
1. 복잡한 UI에서 특정 콘트롤을 활성/비활성화하는 로직이 복잡하다면 TAction을 사용하라.
2. 여러 콘트롤이 동일 동작을 수행해야 한다면, 역시 Action을 사용하라.
델파이 폼 코딩에서 중요한 사항 중 하나가 이벤트 메서드를 최대한 줄이라는 것이다. 그래야만 후일 소스 분석시 여러모로 편리하기 때문이다. TAction은 이런 이벤트 줄이기에 지대한 공헌을 할 수 있고, 코드를 한곳으로 모으는 역할도 한다.
그러나, TAction에는 이보다 더 황당무게하고 재밌는 기능들이 많다. TAction은 거의 콤포넌트같은 역할을 하기 때문에 새로운 TAction타입을 정의할 수도 있다. 이에 관한 다른 고수의 추가글을 기대해 본다.
덧글 : 6 개
김시준 (non) 삭제를 위한 암호를 넣어 주세요
저는 주로 펑션키를 사용할 때 주로 이용을 했었는데.. 많은 도움이 됐습니다.. 2004-06-25
민성기 (non) 삭제를 위한 암호를 넣어 주세요
좋은 글 항상 감사드리고 있습니다~ ^^; 2004-06-26
신동훈 (non) 삭제를 위한 암호를 넣어 주세요
흠 액션은 상당히 좋은 기능입니다 예전에 메신져 만들때 연계되는 UI때문에 코드로 하기 귀찮아서 액션리스트로 해결해버린적이 있습니다. 코드가독성도좋고 괜찮더군요 2004-06-28
신동훈 (non) 삭제를 위한 암호를 넣어 주세요
그리고 액션 리스트 뿐만아니라 액션메니져와 기타 에디셔널 탭에이는 액션관련 컴포넌트도 상당히 괜찮습니다 2004-06-28
전희원 (non) 삭제를 위한 암호를 넣어 주세요
정말 많은 도움이 되었습니다. 2004-07-21
블루판 (myselfcall) 삭제를 위한 암호를 넣어 주세요
소스코드에 형 변환에러가 있더군요
텍스트박스에 임의의값을 넣고 실행하시면됩니다. 2008-02-04 오후 2:48:07
출처: http://www.delmadang.com/community/bbs_view.asp?bbsNo=3&bbsCat=42&indx=196668&keyword1=20가지&keyword2=
소백촌닭
(손님)
2004-10-27 오후 5:13:04
카테고리:팁
5394회 조회
한의원 아저씨로부터 부탁이 있어서 번역을 하게 되었습니다. 번역이 자연스럽게 되면 좋겠는데 어떨지 모르겠네요.
저도 공부하는 거라 생각하고 시작하게 되었습니다.
읽어주셔서 감사합니다.
대부분의 델파이 프로그래머들은 그들의 직접 작업을 하지 않고도 Visual Basic[Editor는 간단히 두려움을 떨쳐버려주지요...]처럼 개발환경을 사용하지요. 델파이는 강력한 VCL 구조와 제각기 델파이 어플리케이션에 객체지향 아키텍쳐의 근본을 두고 있습니다.
이 글에서 필자는 OOP 이론을 주장하려는 것이 아니라 여러분이 프로그램의 구조를 개선하도록 도움될 만한 몇가지 간단한 제안을 할까 합니다. 나열되는 규칙들은 여러분이 작성하는 어플리케이션의 실제 형태에 적용될 수도 안될 수도 있습니다. 그냥 필자가 하는 제안하는 규칙들을 기억해주시면 고맙지요. ^^
제가 제일 강조하는 원칙은 캡슐화인데요. 우리는 프로그램의 다른 부분에 영향을 주지 않고 차후에 코드를 변경할 수 있는 유연성과 내구성이 있는 클래스를 생성하길 바라고 있습니다. 단지 좋은 OOP의 유일한 척도는 아니라도, OOP의 기초라고 할 수 있습니다. 그래서 필자가 이 글에서 정말 OOP를 지나치게 강조하는데에는 몇가지 그럴싸한 이유가 있습니다.
마지막으로, 이러한 원칙들이 델파이 프로그래머에 의해 일상 생활에서 사용된다는 사실을 강조하기 위해서, 필자는 여러가지 규칙들이 컴포넌트의 개발에 똑같이 적용되고 있더라도 주로 폼 개발에 초점을 맞출려고 합니다. 컴포넌트를 작성하는 프로그래머는 특히 OOP와 클래스를 생각해야합니다. 때때로 컴포넌트를 사용하는 프로그래머는 OOP에 관해 잊고 있는데 이 기사가 회상시켜줄 수도 있겠죠.
Part 1: 폼은 곧 클래스다
프로그래머는 오브젝트로서 폼을 취급하죠. 사실, 폼은 클래스인데 말이죠. 여기서 차이점은 동일한 폼 클래스를 바탕으로 다중 폼 오브젝트를 가질 수 있다는 것이죠. 햇갈리는 것은 델파이는 여러분이 정의한 모든 폼 클래스를 기본적으로 글로벌 오브젝트를 생성한다는 것입니다. 이는 프로그래머를 아주 초보적인 것이고 나쁜 습관으로 빠뜨릴 수 있습니다.
Rule 1: 유닛 하나에 클래스 하나!
항상 기억하세요, 클래스의 private과 protected 부분은 단지, 다른 유닛에서 클래스와 프로시저에서는 숨겨진다는 것을 말입니다. 따라서 효과적인 캡슐화를 하려 한다면, 모든 클래스에 대해 각자 다른 유닛을 사용해야 한다는 것입니다. 다른 클래스에서 클래스를 상속하는 간단한 클래스에 대해서는, 실제로 공유 유닛을 사용할 수 있지만, 단지 클래스의 수를 제한한다면: 하나의 유닛에서 20개의 클래스의 복합적인 계층을 위치시키지 말았으면 하는 것이지요. 볼랜드에서 VCL소스 코드에 대량으로 공유 유닛을 작성했을지라도...
폼에 대해 생각하자면, 델파이는 단순히 '한 클래스에 한 유닛' 원칙을 고수하고 프로젝트에 폼이 아닌 클래스를 추가할 때는 새 유닛을 생성하고 있습니다.
Rule 2: 컴포넌트 명
폼이나 유닛에 의미있는 명명을 하는 것은 아주 중요한데요. 안타깝게도, 이 두 명칭은 AboutForm과 About.pas와 같이 이 두가지에 대해 유사한 이름을 주려해도 반드시 달라야 합니다.
또한 컴포넌트에 대한 적당한 명칭 사용도 중요한데요. 가장 일반적인 표기는 btnAdd 나 editName 과 같은 컴포넌트의 역할에 따라, 클래스 타입에 대해 소문자로 머리글자를 사용하는 것입니다. 이 스타일에 따라 실제로 많은 유사한 표기방법이 있는데요. 이 방법을 가장 좋은 방법이라고 할 수는 없겠지만 개인적인 취향이 있는거 아니겠습니까!
Rule 3: 이벤트 명
이벤트 핸들링 메소드에 적당한 명칭을 부여하는 것 또한 쉽게 생각할 일은 아니죠. 예를들어, Button1Click 이라는 컴포넌트명이 있다고 하구요. 메소드명이 버튼명에서 생성되는 것이라고 추측하겠지만, 컴포넌트명에 추가된 메소드명 보다는 메소드의 기능을 잘 설명하는 명칭이 더 나는 방법이라는 생각을 하게 됩니다. 예를들자면, btnAdd 버튼의 OnClick 이벤트는 AddToList라고 할 수도 있겠지요. 이 방법은 특히 클래스의 다른 메소드로부터 이벤트 핸들러를 호출할 때 판독성이 좋아지구요. 필자가 Actions를 사용하는 것이 더 좋다고 말하고 싶지만 같은 메소드를 다양한 이벤트나 다른 컴포넌트에 추가하는데 있어 개발자에게 도움이 됩니다.
Rule 4: 폼 메소드를 사용하자
폼이 클래스라면 그 코드는 메소드로 이루어집니다. 게다가 특별한 역할도 하고 다른 메소드로서도 호출가능한 이벤트 핸들러는 사용자 메소드를 폼 클래스에 추가하는게 종종 유용할게 먹힐 때가 있습니다. 여러분은 폼의 액션을 수행하고 상태를 액세스하는 메소드를 추가할 수도 있습니다. 말하자면, 폼의 컴포넌트를 다른 폼에서 직접 조작하는 것보다는 폼의 public 메소드를 사용하는 것이 더 낫다는 것이지요.
Rule 5: 폼 생성자를 추가하자
실시간에 생성된 두번째 폼은 디폴트로 있는 거 외에 특정 생성자를 작성할 수 있습니다( 상속된 폼 TComponent 클래스). 델파이 이전 버전과 호환이 필요없다면, 필자의 제안은 초기화 파라메터와 함께 Create 메소드를 오버로드(overload)하는 것입니다. 예제 1을 봅니다.
Rule 6: 전역 변수를 피하자
(유닛의 Interface 부분에 선언된) 전역 변수는 되도록 피하도록 합니다. 여기에 괜찮은 제안을 보여주겠습니다.
여러분들 폼에 여분의 데이터 저장공간이 필요하다면, private 필드들을 사용해 보세요. 이 경우에 각 폼 인스턴스는 데이터의 복사본을 가지게 되고, 폼 클래스의 여러 인스턴스들 중에서 공유된 데이터에 대한 유닛 변수들(유닛의 implementation 부분에 선언된)을 여러분이 사용하게 되는 겁니다.
여러분이 다른 타입의 폼들 사이에서 공유된 데이터가 필요하다면, 메인 폼이나 전역 개체에서 데이터를 놓고 데이터를 공유할수도 있고 데이터를 액세스하기 위해 메소드나 프로퍼티를 사용할 수도 있습니다.
Rule 7: TFrom1 에서는 Form1를 사용하지 말자
특정 오브젝트의 클래스의 메소드에서 특정 오브젝트를 참조하지 말아야 합니다. 바꾸어 말하면, TForm1 클래스의 메소드에서 Form1 을 참조하지 마라는 겁니다. 현재 오브젝트에 대한 참조가 필요하다면, Self 키워드를 사용하시면 됩니다. 직접 현재 오브젝트의 메소드와 데이터를 참조할 수 있기 때문에, 대부분의 경우 필요치 않다는 것을 십분 인지 하시기 바랍니다.
여러분이 이 규칙에 따르지 않는다고 봤을 때에는 폼의 여러 인스턴스를 생성할 때 문제 발생의 여지가 많습니다.
Rule 8: 다른 폼에서 Form1을 사용하지 말자
심지어는 다른 폼의 코드에서도 Form1 과 같은 전역 오브젝트에 대한 직접적인 참조를 피하는 것이 좋습니다. 다른 폼에 대한 참조를 로컬 변수나 private 필드로 선언하는게 바람직합니다.
예를들어, 프로그램의 메인폼이 다이얼로그 박스를 참조하는 private 필드를 가질 수 있습니다. 확실히, 이 규칙은 두번째 폼의 여러 이스턴스를 생성하는 것으로 계획한다면 필수적인 것입니다. 이것은 메인 폼의 한 필드에서 리스트를 갖고 있을 수 있고, 그렇지 않으면 전역적인 Screen 오브젝트의 Forms 배열를 사용할 수도 있는 것입니다.
Rule 9: Form1을 제거하자
실제로, 필자의 생각은 델파이에 의해 프로그램에 자동으로 추가된 전역 폼 오브젝트를 제거하는 것입니다. 이것은 단지(델파이에 의해 다시 추가된) 폼의 자동 생성을 불허한다면 가능합니다.
필자의 생각에 전역 폼 오브젝트를 제거한다는 것은 델파이 초보에게도 매우 유용합니다. 클래스와 전역 오브젝트 사이를 혼동하지 않는 초보에게 말이죠. 사실, 전역 오브젝트가 제거된 후, 어떤 참조가 있다면 에러를 초래하게 되겠죠.
Rule 10: 폼 프로퍼티를 추가하자
필자가 이미 언급한 것처럼 폼에 데이터가 필요하면 private 필드를 추가하면 됩니다. 다른 클래스에 대한 액세스가 필요하다면, 그 때는 프로퍼티를 폼에 추가하면 됩니다. 이러한 접근에 따라 여러분은 다른 폼이나 클래스의 코드를 변경하지 않고 그 폼과 데이터(사용자 인터페이스를 포함해서)의 코드를 변경하게 될 것입니다.
Rule 11: 컴포넌트 프로퍼티를 보이자
여러분이 다른 폼의 상태를 액세스하기를 원할 때, 여러분은 그 컴포넌트를 직접 참조하지 않도록 해야합니다. 이 방법은 대부분의 변경에 대한 어플리케이션의 주요 부분중에 하나인 사용자 인터페이스에 다른 폼이나 클래스의 코드를 설정하는 것입니다. 더블어, 컴포넌트 프로퍼티로 맵된 프로퍼티를 선언합니다.
만약 사용자 인터페이스를 변경하고자 한다면, 다른 컴포넌트로 해당 컴포넌트를 대체하세요. 여러분들이 해야할 것은 프로퍼티와 관련된 Get, Set 메소드를 수정하구요. 컴포넌트를 참조할 모든 폼과 클래스의 소스코드를 체크나 수정하지 않아야 합니다. 예제 2를 볼까요.
Rule 12: 프로퍼티 배열
폼안에 연속된 값을 처리할 필요가 있다면, 프로퍼티 배열을 선언하면 됩니다. 이런 경우에는 SpecialForm[3]을 작성해서 직접 값을 액세스 할 수 있도록 폼의 기본 프로퍼티 배열을 만들수 있다는 것은 폼에는 대단히 중요한 정보입니다.
예제 3에서는 프로퍼티 배열을 다루는 폼의 기본 배열 프로퍼티로서 listbox의 아이템을 어떻게 나타내는지 보여주고 있습니다.
Rule 13: 프로퍼티의 부과효과를 사용하자
전역 변수를 사용하는 대신, 프로퍼티의 장점중에 하나가 프로퍼티의 값을 읽거나 쓸 때 부과효과가 나타날 수 있다는 것을 알아두세요.
예를들면, 여러분이 폼에 직접 그리고, 다양한 프로퍼티의 값을 설정하고, 특별한 메소드를 호출하며, 한번에 여러 컴포넌트의 상태를 변경할 수 있다는 것인데 가능하다면 이벤트를 발생하는 것이죠.
Rule 14: 컴포넌트를 숨기자
필자는 캡슐화의 원칙을 따르지 않는 방식인 published 섹션에서 컴포넌트의 리스트를 포함하는 델파이 폼 때문에 OOP 추종자들이 불평하는 소리를 너무나 자주 들어왔습니다. 그들은 실제로 중요한 문제를 지적하고 있지만 그들의 대부분은 델파이를 재작성하지 않거나 언어를 변경하지 않고 해결책이 가까이에 있다는 것을 인지하지 못하는 것 같습니다.
델파이는 폼에 추가할 수 있는 컴포넌트 레퍼런스가 private 부분으로 이동할 수 있다는 것 입니다. 다른폼에서 액세스하지 못하도록 말이죠. 컴포넌트의 상태를 액세스 하도록 (규칙 11)컴포넌트 맵된 프로퍼티를 의무적으로 사용을 하게 하는 방법입니다.
델파이가 published 섹션에 컴포넌트를 위치하는건 이러한 필드가 *.DFM 파일로부터 생성된 컴포넌트를 설정하는 방법 때문이죠. 컴포넌트 명을 설정할 때 VCL은 자동으로 폼에 컴포넌트의 오브젝트를 그 레퍼런스에 추가합니다. 델파이가 이를 수행하기 위해 RTTI와 TObject 메소드를 사용하기 때문에 레퍼런스가 published 되는 이유이죠.
더욱 자세하게 살펴보고 싶다면 InsertComponent, RemoveComponent, 그리고 SetName에 의해 호출된 TComponent 클래스의 SetReference 메소드의 코드를 가진 예제 4를 참조하세요.
여러분이 이해를 했다면, published에서 private 섹션으로 컴포넌트 레퍼런스를 이동해서 이런 자동적인 작업을 벗어나게 됩니다. 이런한 문제를 해결하기 위해서 단순히 폼 OnCreate 이벤트 핸들러에 각 컴포넌트에 대해 아래와 같은 코드를 추가를 합니다.
Edit1 := FindComponent(.Edit1.)As TEdit;
다음으로 해야할 일은 시스템에서 컴포넌트 클래스를 등록하는 것 입니다. RTTI 정보가 컴파일된 프로그램에 포함되고 시스템에서 이용될 수 있도록 말이죠. 모든 컴포넌트 클래스에 대해서 단지 한번이면 됩니다. private 섹션에 컴포넌트 레퍼런스 타입을 이동한다면 말이죠. 여러분은 이 작업이 필요하지 않더라도 RegisterClasses 메소드에 대한 추가적인 호출이 무해하기 때문에 이러한 호출을 추가할 수 있습니다. RegisterCalsses 메소드는 흔히 폼을 다루는 유닛의 initialization 섹션에 추가되고 있습니다.
RegisterClasses([TEdit]);
Rule 15: OOP Form Wiard
모든 폼의 모든 컴포넌트에 대해 위의 두가지 방법을 반복한다면 아주 지루하고 시간낭비가 아닐 수 없습니다. 이런 과중한(?) 부담을 피하기 위해서 필자는 작은 윈도우에서 프로그램에 추가할 수 있는 코드의 라인을 생성하는 간단한 wizard를 작성했습니다. 각 폼에 대해 두번의 Copy & Paste 작업을 할 필요가 있습니다.
Wizard는 적당한 위치에 자동으로 소스코드를 배치하지는 않습니다: 필자는 update 버전을 만들면서 필자의 웹사이트 (http://www.marcocantu.com)에 올려놓고 있습니다.
Part 2: 상속
위의 규칙들이 클래스, 특별히 폼 클래스에 집중되어 있지만 이제부터는 상속과 비주얼 폼 상속에 관련된 간단한 제안과 팁들을 볼 수 있습니다.
Rule 16: 비주얼 폼 상속
상속성이란 적당히 사용하면, 강력한 메카니즘입니다. 필자의 경험으로 비추어 볼 때, 이 가치는 프로젝트의 단위가 커질수록 상승합니다. 복잡한 프로그램에서 다형성과 함께 폼 그룹상에 작용하는 폼들 사이에 계층관계를 사용할 수 있습니다.
비주얼 폼 상속은 다양한 폼의 일반적인 작업의 공유가 가능하게 합니다: 메소드, 프로퍼티, 이벤트 핸들러, 컴포넌트 이벤트 핸들러 등.
Rule 17: Protected 데이터의 제한
클래스 계층을 작성할 때, 어떤 프로그래머들은 private 필드들이 서브클래스에서 액세스 되지 않기 때문에 주로 protected 필드를 사용하는 경향이 있습니다. 필자는 이것이 나쁘다고 말하고 싶지는 않지만 캡슐화의 개념과는 상반되는 것입니다. protected 데이터의 구현은 모든 상속된 폼들에서 공유됩니다. 데이터의 오리지날 정의에서의 변경 같은 경우에도 모든 것을 업데이트 해야할지도 모르죠.
규칙 14의 컴포넌트 숨기기를 따른다면, 상속된 폼은 상위 클래스의 private 컴포넌트를 액세스 할 수 없다는 것을 명심하세요. 상속된 폼에서는 "Edit1.Text := ..;"와 같은 코드가 더이상 컴파일 되지 않습니다. 필자는 이러한 것이 매울 불편하지만, 적어도 이론상으로는 나쁘지 않다고 봅니다. 캡슐화에 대한 특권이 과하다면, 상위 폼에 protected 섹션에서 컴포넌트 레퍼런스를 선언하세요.
Rule 18: Protected 액세스 메소드
private섹션에서 컴포넌트 레퍼런스를 배치하는게 더 좋고, 상위 클래스에 컴포넌트 프로퍼티를 액세스 함수를 추가하는 것도 좋지요. 이러한 액세스 함수는 단지 내부적으로 사용되고 클래스 인터페이스 부분이 아니면, protected로서 이들을 선언해야 하지요. 예를 들자면, 규칙 11에 서술된 GetText, SetText 폼 메소드는 protected되고 호출에 의해 edit text를 액세스할 수 있게 됩니다:
SetText(..);
실제로, 메소드가 프로퍼티로 맵되기 때문에, 우리는 단순히 아래와 같이 작성합니다:
Text := ..;
Rule 19: Protected 가상 메소드
유연한 계층을 위한 또 다른 키 포인트는 다형성을 갖는 외부 클래스로부터 호출할 수 있는 가상 메소드를 선언하는 것입니다. 이를 일반적인 접근법이라고 한다면, 다른 public 메소드로 호출된 protected 가상 메소드를 자주 볼 수는 없습니다. 이는 오브젝트의 작업을 수정하면서 상속된 클래스에서 가상 메소드를 조작할 수 있기에 중요한 테크닉이 됩니다.
Rule 20: 프로퍼티를 위한 가상 메소드
프로퍼티 액세스 메소드는 상속된 클래스가 프로퍼티를 재정의하지 않고 프로퍼티의 작업을 변경할 수 있도록 가상으로 선언될 수 있습니다. 이러한 접근법은 VCL에서는 거의 사용되지 않지만 매우 유연하고 강력합니다. 이를 구현하기 위해, 단순히 규칙 11의 Get, Set 메소드를 가상으로 선언하면 됩니다. 상위 폼은 예제 5 코드를 갖게 될 겁니다.
상속된 폼에서 여러분은 몇가지 기능추가로 가상 메소드 SetText를 override할 수 있습니다:
The Code
이 강좌에서 모든 코드는 이달의 디스크에 포함된 OOPDemo 예제 프로젝트에 있습니다. 두번째 폼(frm2 유닛)을 체크하고 상속된 폼(inherited unit)도 체크해보세요. initialization 코드와 private 컴포넌트 레퍼런스로 동시에 조작된 생성자를 사용하기 위해 폼의 OldCreateOrder 프로퍼티를 설정해야 한다는 것을 명심하세요. 그렇지 않으면 폼 생성자(컴포넌트를 사용하는)에서 initialization 코드는 실제 컴포넌트에 레퍼런스로 연결하는 폼의 OnCreate 메소드 이전에 실행될 것입니다.
디스크상에서 OOP Form Wizard라는 첫 작품의 컴파일된 팩키지를 볼 수 있습니다만 필자의 홈페이지에서 업데이트된 버전을 찾는게 훨씬 나을 것입니다.
Conclusion
훌륭한 OOP 원칙에 따라 델파이로 프로그래밍은 필지가 강조한 규칙들의 명확함과는 동떨어져 있습니다. 규칙은 적당한 내용으로 적용되어야 하고 규칙에 따라 작업하는 다수의 프로그래머 사이에 어플리케이션의 크기가 성장하는 만큼 더 중요합니다. 작은 프로그램을 개발하는데 있어도 필자가 주장하는 규칙의 OOP의 원칙(무엇보다 캡슐화)을 기억한다는 것은 실제로 도움이 될 것 입니다.
특정 기사가 될만큼 아주 복잡한 RTTI 이슈와 메모리 핸들링에 익숙하지 않았기 때문에 여러분이 배울 수 있는 다양한 규칙들이 있겠지요.
필자의 결론은 필자가 강조했던 규칙들이 추가적 코드에 의하여 대가를 필요로 하는 것이죠: 더 유연하고 내구성있는 프로그램을 얻고자 지불해야하는 값어치 말입니다. 미래의 델파이 버전은 우리가 고생을 덜 하도록 도움을 주리라 믿습니다.
Marco Cantu는 Mastering Delphi Series, Delphi Developer's Handbook, 그리고 무료 온라인 북 Essential Pascal의 작가입니다. 그는 델파이 기초와 고급과정을 가르치고 있습니다. 더 자세한 사항은 그의 홈페이지 http://www.marcocantu.com 에서 확인하시길 바랍니다. 여러분은 그의 공개 뉴스그룹에서 그를 볼 수 있습니다: 상세한 정보는 그의 홈페이지를 보세요.
소백촌닭
(손님)
2004-10-27 오후 5:13:04
카테고리:팁
5394회 조회
한의원 아저씨로부터 부탁이 있어서 번역을 하게 되었습니다. 번역이 자연스럽게 되면 좋겠는데 어떨지 모르겠네요.
저도 공부하는 거라 생각하고 시작하게 되었습니다.
읽어주셔서 감사합니다.
대부분의 델파이 프로그래머들은 그들의 직접 작업을 하지 않고도 Visual Basic[Editor는 간단히 두려움을 떨쳐버려주지요...]처럼 개발환경을 사용하지요. 델파이는 강력한 VCL 구조와 제각기 델파이 어플리케이션에 객체지향 아키텍쳐의 근본을 두고 있습니다.
이 글에서 필자는 OOP 이론을 주장하려는 것이 아니라 여러분이 프로그램의 구조를 개선하도록 도움될 만한 몇가지 간단한 제안을 할까 합니다. 나열되는 규칙들은 여러분이 작성하는 어플리케이션의 실제 형태에 적용될 수도 안될 수도 있습니다. 그냥 필자가 하는 제안하는 규칙들을 기억해주시면 고맙지요. ^^
제가 제일 강조하는 원칙은 캡슐화인데요. 우리는 프로그램의 다른 부분에 영향을 주지 않고 차후에 코드를 변경할 수 있는 유연성과 내구성이 있는 클래스를 생성하길 바라고 있습니다. 단지 좋은 OOP의 유일한 척도는 아니라도, OOP의 기초라고 할 수 있습니다. 그래서 필자가 이 글에서 정말 OOP를 지나치게 강조하는데에는 몇가지 그럴싸한 이유가 있습니다.
마지막으로, 이러한 원칙들이 델파이 프로그래머에 의해 일상 생활에서 사용된다는 사실을 강조하기 위해서, 필자는 여러가지 규칙들이 컴포넌트의 개발에 똑같이 적용되고 있더라도 주로 폼 개발에 초점을 맞출려고 합니다. 컴포넌트를 작성하는 프로그래머는 특히 OOP와 클래스를 생각해야합니다. 때때로 컴포넌트를 사용하는 프로그래머는 OOP에 관해 잊고 있는데 이 기사가 회상시켜줄 수도 있겠죠.
Part 1: 폼은 곧 클래스다
프로그래머는 오브젝트로서 폼을 취급하죠. 사실, 폼은 클래스인데 말이죠. 여기서 차이점은 동일한 폼 클래스를 바탕으로 다중 폼 오브젝트를 가질 수 있다는 것이죠. 햇갈리는 것은 델파이는 여러분이 정의한 모든 폼 클래스를 기본적으로 글로벌 오브젝트를 생성한다는 것입니다. 이는 프로그래머를 아주 초보적인 것이고 나쁜 습관으로 빠뜨릴 수 있습니다.
Rule 1: 유닛 하나에 클래스 하나!
항상 기억하세요, 클래스의 private과 protected 부분은 단지, 다른 유닛에서 클래스와 프로시저에서는 숨겨진다는 것을 말입니다. 따라서 효과적인 캡슐화를 하려 한다면, 모든 클래스에 대해 각자 다른 유닛을 사용해야 한다는 것입니다. 다른 클래스에서 클래스를 상속하는 간단한 클래스에 대해서는, 실제로 공유 유닛을 사용할 수 있지만, 단지 클래스의 수를 제한한다면: 하나의 유닛에서 20개의 클래스의 복합적인 계층을 위치시키지 말았으면 하는 것이지요. 볼랜드에서 VCL소스 코드에 대량으로 공유 유닛을 작성했을지라도...
폼에 대해 생각하자면, 델파이는 단순히 '한 클래스에 한 유닛' 원칙을 고수하고 프로젝트에 폼이 아닌 클래스를 추가할 때는 새 유닛을 생성하고 있습니다.
Rule 2: 컴포넌트 명
폼이나 유닛에 의미있는 명명을 하는 것은 아주 중요한데요. 안타깝게도, 이 두 명칭은 AboutForm과 About.pas와 같이 이 두가지에 대해 유사한 이름을 주려해도 반드시 달라야 합니다.
또한 컴포넌트에 대한 적당한 명칭 사용도 중요한데요. 가장 일반적인 표기는 btnAdd 나 editName 과 같은 컴포넌트의 역할에 따라, 클래스 타입에 대해 소문자로 머리글자를 사용하는 것입니다. 이 스타일에 따라 실제로 많은 유사한 표기방법이 있는데요. 이 방법을 가장 좋은 방법이라고 할 수는 없겠지만 개인적인 취향이 있는거 아니겠습니까!
Rule 3: 이벤트 명
이벤트 핸들링 메소드에 적당한 명칭을 부여하는 것 또한 쉽게 생각할 일은 아니죠. 예를들어, Button1Click 이라는 컴포넌트명이 있다고 하구요. 메소드명이 버튼명에서 생성되는 것이라고 추측하겠지만, 컴포넌트명에 추가된 메소드명 보다는 메소드의 기능을 잘 설명하는 명칭이 더 나는 방법이라는 생각을 하게 됩니다. 예를들자면, btnAdd 버튼의 OnClick 이벤트는 AddToList라고 할 수도 있겠지요. 이 방법은 특히 클래스의 다른 메소드로부터 이벤트 핸들러를 호출할 때 판독성이 좋아지구요. 필자가 Actions를 사용하는 것이 더 좋다고 말하고 싶지만 같은 메소드를 다양한 이벤트나 다른 컴포넌트에 추가하는데 있어 개발자에게 도움이 됩니다.
Rule 4: 폼 메소드를 사용하자
폼이 클래스라면 그 코드는 메소드로 이루어집니다. 게다가 특별한 역할도 하고 다른 메소드로서도 호출가능한 이벤트 핸들러는 사용자 메소드를 폼 클래스에 추가하는게 종종 유용할게 먹힐 때가 있습니다. 여러분은 폼의 액션을 수행하고 상태를 액세스하는 메소드를 추가할 수도 있습니다. 말하자면, 폼의 컴포넌트를 다른 폼에서 직접 조작하는 것보다는 폼의 public 메소드를 사용하는 것이 더 낫다는 것이지요.
Rule 5: 폼 생성자를 추가하자
실시간에 생성된 두번째 폼은 디폴트로 있는 거 외에 특정 생성자를 작성할 수 있습니다( 상속된 폼 TComponent 클래스). 델파이 이전 버전과 호환이 필요없다면, 필자의 제안은 초기화 파라메터와 함께 Create 메소드를 오버로드(overload)하는 것입니다. 예제 1을 봅니다.
|
Rule 6: 전역 변수를 피하자
(유닛의 Interface 부분에 선언된) 전역 변수는 되도록 피하도록 합니다. 여기에 괜찮은 제안을 보여주겠습니다.
여러분들 폼에 여분의 데이터 저장공간이 필요하다면, private 필드들을 사용해 보세요. 이 경우에 각 폼 인스턴스는 데이터의 복사본을 가지게 되고, 폼 클래스의 여러 인스턴스들 중에서 공유된 데이터에 대한 유닛 변수들(유닛의 implementation 부분에 선언된)을 여러분이 사용하게 되는 겁니다.
여러분이 다른 타입의 폼들 사이에서 공유된 데이터가 필요하다면, 메인 폼이나 전역 개체에서 데이터를 놓고 데이터를 공유할수도 있고 데이터를 액세스하기 위해 메소드나 프로퍼티를 사용할 수도 있습니다.
Rule 7: TFrom1 에서는 Form1를 사용하지 말자
특정 오브젝트의 클래스의 메소드에서 특정 오브젝트를 참조하지 말아야 합니다. 바꾸어 말하면, TForm1 클래스의 메소드에서 Form1 을 참조하지 마라는 겁니다. 현재 오브젝트에 대한 참조가 필요하다면, Self 키워드를 사용하시면 됩니다. 직접 현재 오브젝트의 메소드와 데이터를 참조할 수 있기 때문에, 대부분의 경우 필요치 않다는 것을 십분 인지 하시기 바랍니다.
여러분이 이 규칙에 따르지 않는다고 봤을 때에는 폼의 여러 인스턴스를 생성할 때 문제 발생의 여지가 많습니다.
Rule 8: 다른 폼에서 Form1을 사용하지 말자
심지어는 다른 폼의 코드에서도 Form1 과 같은 전역 오브젝트에 대한 직접적인 참조를 피하는 것이 좋습니다. 다른 폼에 대한 참조를 로컬 변수나 private 필드로 선언하는게 바람직합니다.
예를들어, 프로그램의 메인폼이 다이얼로그 박스를 참조하는 private 필드를 가질 수 있습니다. 확실히, 이 규칙은 두번째 폼의 여러 이스턴스를 생성하는 것으로 계획한다면 필수적인 것입니다. 이것은 메인 폼의 한 필드에서 리스트를 갖고 있을 수 있고, 그렇지 않으면 전역적인 Screen 오브젝트의 Forms 배열를 사용할 수도 있는 것입니다.
Rule 9: Form1을 제거하자
실제로, 필자의 생각은 델파이에 의해 프로그램에 자동으로 추가된 전역 폼 오브젝트를 제거하는 것입니다. 이것은 단지(델파이에 의해 다시 추가된) 폼의 자동 생성을 불허한다면 가능합니다.
필자의 생각에 전역 폼 오브젝트를 제거한다는 것은 델파이 초보에게도 매우 유용합니다. 클래스와 전역 오브젝트 사이를 혼동하지 않는 초보에게 말이죠. 사실, 전역 오브젝트가 제거된 후, 어떤 참조가 있다면 에러를 초래하게 되겠죠.
Rule 10: 폼 프로퍼티를 추가하자
필자가 이미 언급한 것처럼 폼에 데이터가 필요하면 private 필드를 추가하면 됩니다. 다른 클래스에 대한 액세스가 필요하다면, 그 때는 프로퍼티를 폼에 추가하면 됩니다. 이러한 접근에 따라 여러분은 다른 폼이나 클래스의 코드를 변경하지 않고 그 폼과 데이터(사용자 인터페이스를 포함해서)의 코드를 변경하게 될 것입니다.
두번째 폼이나 다이알로그 박스 초기화를 위해서나 마지막 값을 얻기 위해 프로퍼티나 메소드를 사용할 수 있습니다. 초기화라는 것은 위에서 언급했듯이 생성자를 사용해서 수행할 수 있습니다.
Rule 11: 컴포넌트 프로퍼티를 보이자
여러분이 다른 폼의 상태를 액세스하기를 원할 때, 여러분은 그 컴포넌트를 직접 참조하지 않도록 해야합니다. 이 방법은 대부분의 변경에 대한 어플리케이션의 주요 부분중에 하나인 사용자 인터페이스에 다른 폼이나 클래스의 코드를 설정하는 것입니다. 더블어, 컴포넌트 프로퍼티로 맵된 프로퍼티를 선언합니다.
만약 사용자 인터페이스를 변경하고자 한다면, 다른 컴포넌트로 해당 컴포넌트를 대체하세요. 여러분들이 해야할 것은 프로퍼티와 관련된 Get, Set 메소드를 수정하구요. 컴포넌트를 참조할 모든 폼과 클래스의 소스코드를 체크나 수정하지 않아야 합니다. 예제 2를 볼까요.
|
Rule 12: 프로퍼티 배열
폼안에 연속된 값을 처리할 필요가 있다면, 프로퍼티 배열을 선언하면 됩니다. 이런 경우에는 SpecialForm[3]을 작성해서 직접 값을 액세스 할 수 있도록 폼의 기본 프로퍼티 배열을 만들수 있다는 것은 폼에는 대단히 중요한 정보입니다.
예제 3에서는 프로퍼티 배열을 다루는 폼의 기본 배열 프로퍼티로서 listbox의 아이템을 어떻게 나타내는지 보여주고 있습니다.
|
Rule 13: 프로퍼티의 부과효과를 사용하자
전역 변수를 사용하는 대신, 프로퍼티의 장점중에 하나가 프로퍼티의 값을 읽거나 쓸 때 부과효과가 나타날 수 있다는 것을 알아두세요.
예를들면, 여러분이 폼에 직접 그리고, 다양한 프로퍼티의 값을 설정하고, 특별한 메소드를 호출하며, 한번에 여러 컴포넌트의 상태를 변경할 수 있다는 것인데 가능하다면 이벤트를 발생하는 것이죠.
Rule 14: 컴포넌트를 숨기자
필자는 캡슐화의 원칙을 따르지 않는 방식인 published 섹션에서 컴포넌트의 리스트를 포함하는 델파이 폼 때문에 OOP 추종자들이 불평하는 소리를 너무나 자주 들어왔습니다. 그들은 실제로 중요한 문제를 지적하고 있지만 그들의 대부분은 델파이를 재작성하지 않거나 언어를 변경하지 않고 해결책이 가까이에 있다는 것을 인지하지 못하는 것 같습니다.
델파이는 폼에 추가할 수 있는 컴포넌트 레퍼런스가 private 부분으로 이동할 수 있다는 것 입니다. 다른폼에서 액세스하지 못하도록 말이죠. 컴포넌트의 상태를 액세스 하도록 (규칙 11)컴포넌트 맵된 프로퍼티를 의무적으로 사용을 하게 하는 방법입니다.
델파이가 published 섹션에 컴포넌트를 위치하는건 이러한 필드가 *.DFM 파일로부터 생성된 컴포넌트를 설정하는 방법 때문이죠. 컴포넌트 명을 설정할 때 VCL은 자동으로 폼에 컴포넌트의 오브젝트를 그 레퍼런스에 추가합니다. 델파이가 이를 수행하기 위해 RTTI와 TObject 메소드를 사용하기 때문에 레퍼런스가 published 되는 이유이죠.
더욱 자세하게 살펴보고 싶다면 InsertComponent, RemoveComponent, 그리고 SetName에 의해 호출된 TComponent 클래스의 SetReference 메소드의 코드를 가진 예제 4를 참조하세요.
여러분이 이해를 했다면, published에서 private 섹션으로 컴포넌트 레퍼런스를 이동해서 이런 자동적인 작업을 벗어나게 됩니다. 이런한 문제를 해결하기 위해서 단순히 폼 OnCreate 이벤트 핸들러에 각 컴포넌트에 대해 아래와 같은 코드를 추가를 합니다.
Edit1 := FindComponent(.Edit1.)As TEdit;
다음으로 해야할 일은 시스템에서 컴포넌트 클래스를 등록하는 것 입니다. RTTI 정보가 컴파일된 프로그램에 포함되고 시스템에서 이용될 수 있도록 말이죠. 모든 컴포넌트 클래스에 대해서 단지 한번이면 됩니다. private 섹션에 컴포넌트 레퍼런스 타입을 이동한다면 말이죠. 여러분은 이 작업이 필요하지 않더라도 RegisterClasses 메소드에 대한 추가적인 호출이 무해하기 때문에 이러한 호출을 추가할 수 있습니다. RegisterCalsses 메소드는 흔히 폼을 다루는 유닛의 initialization 섹션에 추가되고 있습니다.
RegisterClasses([TEdit]);
|
Rule 15: OOP Form Wiard
모든 폼의 모든 컴포넌트에 대해 위의 두가지 방법을 반복한다면 아주 지루하고 시간낭비가 아닐 수 없습니다. 이런 과중한(?) 부담을 피하기 위해서 필자는 작은 윈도우에서 프로그램에 추가할 수 있는 코드의 라인을 생성하는 간단한 wizard를 작성했습니다. 각 폼에 대해 두번의 Copy & Paste 작업을 할 필요가 있습니다.
Wizard는 적당한 위치에 자동으로 소스코드를 배치하지는 않습니다: 필자는 update 버전을 만들면서 필자의 웹사이트 (http://www.marcocantu.com)에 올려놓고 있습니다.
Part 2: 상속
위의 규칙들이 클래스, 특별히 폼 클래스에 집중되어 있지만 이제부터는 상속과 비주얼 폼 상속에 관련된 간단한 제안과 팁들을 볼 수 있습니다.
Rule 16: 비주얼 폼 상속
상속성이란 적당히 사용하면, 강력한 메카니즘입니다. 필자의 경험으로 비추어 볼 때, 이 가치는 프로젝트의 단위가 커질수록 상승합니다. 복잡한 프로그램에서 다형성과 함께 폼 그룹상에 작용하는 폼들 사이에 계층관계를 사용할 수 있습니다.
비주얼 폼 상속은 다양한 폼의 일반적인 작업의 공유가 가능하게 합니다: 메소드, 프로퍼티, 이벤트 핸들러, 컴포넌트 이벤트 핸들러 등.
Rule 17: Protected 데이터의 제한
클래스 계층을 작성할 때, 어떤 프로그래머들은 private 필드들이 서브클래스에서 액세스 되지 않기 때문에 주로 protected 필드를 사용하는 경향이 있습니다. 필자는 이것이 나쁘다고 말하고 싶지는 않지만 캡슐화의 개념과는 상반되는 것입니다. protected 데이터의 구현은 모든 상속된 폼들에서 공유됩니다. 데이터의 오리지날 정의에서의 변경 같은 경우에도 모든 것을 업데이트 해야할지도 모르죠.
규칙 14의 컴포넌트 숨기기를 따른다면, 상속된 폼은 상위 클래스의 private 컴포넌트를 액세스 할 수 없다는 것을 명심하세요. 상속된 폼에서는 "Edit1.Text := ..;"와 같은 코드가 더이상 컴파일 되지 않습니다. 필자는 이러한 것이 매울 불편하지만, 적어도 이론상으로는 나쁘지 않다고 봅니다. 캡슐화에 대한 특권이 과하다면, 상위 폼에 protected 섹션에서 컴포넌트 레퍼런스를 선언하세요.
Rule 18: Protected 액세스 메소드
private섹션에서 컴포넌트 레퍼런스를 배치하는게 더 좋고, 상위 클래스에 컴포넌트 프로퍼티를 액세스 함수를 추가하는 것도 좋지요. 이러한 액세스 함수는 단지 내부적으로 사용되고 클래스 인터페이스 부분이 아니면, protected로서 이들을 선언해야 하지요. 예를 들자면, 규칙 11에 서술된 GetText, SetText 폼 메소드는 protected되고 호출에 의해 edit text를 액세스할 수 있게 됩니다:
SetText(..);
실제로, 메소드가 프로퍼티로 맵되기 때문에, 우리는 단순히 아래와 같이 작성합니다:
Text := ..;
Rule 19: Protected 가상 메소드
유연한 계층을 위한 또 다른 키 포인트는 다형성을 갖는 외부 클래스로부터 호출할 수 있는 가상 메소드를 선언하는 것입니다. 이를 일반적인 접근법이라고 한다면, 다른 public 메소드로 호출된 protected 가상 메소드를 자주 볼 수는 없습니다. 이는 오브젝트의 작업을 수정하면서 상속된 클래스에서 가상 메소드를 조작할 수 있기에 중요한 테크닉이 됩니다.
Rule 20: 프로퍼티를 위한 가상 메소드
프로퍼티 액세스 메소드는 상속된 클래스가 프로퍼티를 재정의하지 않고 프로퍼티의 작업을 변경할 수 있도록 가상으로 선언될 수 있습니다. 이러한 접근법은 VCL에서는 거의 사용되지 않지만 매우 유연하고 강력합니다. 이를 구현하기 위해, 단순히 규칙 11의 Get, Set 메소드를 가상으로 선언하면 됩니다. 상위 폼은 예제 5 코드를 갖게 될 겁니다.
상속된 폼에서 여러분은 몇가지 기능추가로 가상 메소드 SetText를 override할 수 있습니다:
procedure TFromInherit.SetTetx(Const Value: String);
begin
inherited SetText (Value);
if Value = .. then
Button1.Enabled := False;
end;
|
The Code
이 강좌에서 모든 코드는 이달의 디스크에 포함된 OOPDemo 예제 프로젝트에 있습니다. 두번째 폼(frm2 유닛)을 체크하고 상속된 폼(inherited unit)도 체크해보세요. initialization 코드와 private 컴포넌트 레퍼런스로 동시에 조작된 생성자를 사용하기 위해 폼의 OldCreateOrder 프로퍼티를 설정해야 한다는 것을 명심하세요. 그렇지 않으면 폼 생성자(컴포넌트를 사용하는)에서 initialization 코드는 실제 컴포넌트에 레퍼런스로 연결하는 폼의 OnCreate 메소드 이전에 실행될 것입니다.
디스크상에서 OOP Form Wizard라는 첫 작품의 컴파일된 팩키지를 볼 수 있습니다만 필자의 홈페이지에서 업데이트된 버전을 찾는게 훨씬 나을 것입니다.
Conclusion
훌륭한 OOP 원칙에 따라 델파이로 프로그래밍은 필지가 강조한 규칙들의 명확함과는 동떨어져 있습니다. 규칙은 적당한 내용으로 적용되어야 하고 규칙에 따라 작업하는 다수의 프로그래머 사이에 어플리케이션의 크기가 성장하는 만큼 더 중요합니다. 작은 프로그램을 개발하는데 있어도 필자가 주장하는 규칙의 OOP의 원칙(무엇보다 캡슐화)을 기억한다는 것은 실제로 도움이 될 것 입니다.
특정 기사가 될만큼 아주 복잡한 RTTI 이슈와 메모리 핸들링에 익숙하지 않았기 때문에 여러분이 배울 수 있는 다양한 규칙들이 있겠지요.
필자의 결론은 필자가 강조했던 규칙들이 추가적 코드에 의하여 대가를 필요로 하는 것이죠: 더 유연하고 내구성있는 프로그램을 얻고자 지불해야하는 값어치 말입니다. 미래의 델파이 버전은 우리가 고생을 덜 하도록 도움을 주리라 믿습니다.
Marco Cantu는 Mastering Delphi Series, Delphi Developer's Handbook, 그리고 무료 온라인 북 Essential Pascal의 작가입니다. 그는 델파이 기초와 고급과정을 가르치고 있습니다. 더 자세한 사항은 그의 홈페이지 http://www.marcocantu.com 에서 확인하시길 바랍니다. 여러분은 그의 공개 뉴스그룹에서 그를 볼 수 있습니다: 상세한 정보는 그의 홈페이지를 보세요.
from: http://msdn.microsoft.com/ko-kr/magazine/cc163418.aspx
개발자로서의 자부심
Adam Barr
대학 졸업반 시절 컴
퓨터 과학을 전공하고 투자 은행에 취직하게 된 동기생과 나누었던 대화가 기억에 남습니다. 그는 소프트웨어 설계 분야의 일을 하고
싶지만 실제 소프트웨어를 작성하는 평범한 일에 매달리고 싶지는 않다고 말했습니다. 그런 일은 한 단계 아래의 코더들에게 맡기면
된다는 얘기였습니다. 필자 같은 사람에게 말이지요. 자유자재로 코드를 다루는 능력이 곧 최고를 의미하는 대학 분위기에 익숙했던
필자는 이 말에 왠지 모를 모욕감을 느꼈습니다.
어쨌든 그의 의견에도 나름의 일리는 있었습니다. 당시 필자는 그저 코더에 불과했습니다(그 친구 역시 다를 바 없었지만). 하지만 Mike Gunderloy가 집필한 Coder to Developer라
는 책의 제목처럼, 이제 필자는 스스로를 단순한 코더 이상의 개발자라고 생각합니다. 필자는 단순히 컴파일되는 코드를 작성하는
방법 외에도 많은 지식을 갖고 있습니다. 즉, 빠르고 안정적이며 충분한 테스트를 거치고 안전하며 유지 관리가 용이하고 다른
언어에서도 사용할 수 있는 소프트웨어를 만들 수 있고 성능이 뛰어난 코드의 특성을 나열할 수도 있습니다. 전반적으로 소프트웨어
산업은 코더 집단에서 개발자 집단으로 성숙하는 과정에 있습니다.
지
금 개발자에게 향후 하고 싶은 일을 물어보면 설계자라고 대답할 것입니다. 설계자라는 단어는 뭔가 고급스럽고 전문적인 인상을
주며, 이 단어를 듣고 나면 개발자라는 말은 단순 노무자처럼 느껴지게 됩니다. 그렇다면 필자도 이론적인 다음 단계에 따라
스스로를 설계자로 칭할까요? 그렇지 않습니다.
물
론 설계자를 모욕하려는 의도는 없습니다. 소프트웨어 개발을 위해서는 시스템 구성 요소 간의 상호 작용을 설계하고 전체적인 구조를
파악하고 있는 사람이 필요합니다. 그렇지만 필자는 개발자라는 사실에 자부심을 느끼며, 다른 모든 개발자들도 이러한 자부심을 갖길
희망합니다.
Frank
Gehry나 Rem Koolhaas와 같은 건축 설계자가 누리는 디자인의 자유가 부럽습니까? 이에 대한 필자의 답은 소프트웨어
엔지니어링 분야는 아직 이러한 개념적 단계에 오를 만큼 발전하지는 않았다는 것입니다. 건축 설계자들이 빌바오 구겐하임 박물관,
시에틀 공공 도서관과 같은 건축물을 디자인할 수 있는 것은 토목 공학에 관한 수 세기에 걸친 지식이 밑받침이 되었기 때문입니다.
소프트웨어 산업에서는 아직 이 정도 수준에서 작업할 정도의 호사를 누릴 수 없습니다. 우리들 대부분은 여전히 '현관문을 세게
닫아도 무너지지 않는 1층짜리 집'을 짓고 있을 뿐입니다.
Microsoft
는 버그의 원인을 조사하는 과정에서 버그의 상당수는 설계자가 설계 문서를 검토하면서 발견할 수 있는 설계상의 버그도 아니고,
소스 코드가 프로그래머의 의도대로 동작하지 않는 코딩 버그도 아니라는 점을 알게 되었습니다. 양쪽 모두에 속하지 않는 이러한
버그는 소스 코드는 프로그래머의 의도대로 동작하지만 그 의도에 국부적인 오류가 있는 경우에 발생합니다. 메서드에 잘못된 플래그를
전달하거나 구성 매개 변수의 의미를 잘못 이해하는 문제가 여기에 해당합니다. 이는 설계자의 영역이 아닙니다. 우리 개발자들
스스로가 올바르게 수행해야 할 부분입니다.
Fred
Brooks는 이에 대해 그의 유명한 평론인 "No Silver Bullet(만능 열쇠는 없다)"에서 "소프트웨어 엔터티의
본질은 데이터 집합, 데이터 항목 간의 관계, 알고리즘, 그리고 함수 호출이라는 상호 연동 개념들의 조립 구조"라며 "소프트웨어
구축의 어려운 부분은 이러한 개념적 구조의 사양 작성, 설계, 그리고 테스트에 있는 것이며 이러한 구조를 표현하고 이 표현의
충실성을 테스트하는 노력에 있는 것은 아니다"라고 말했습니다. 그는 설계자가 할 일이 아니라 개발자가 할 일을 말하는 것입니다.
즉, 코더가 되기는 쉽지만 개발자가 되기는 어렵다는 말입니다. 개발자는 개발자의 작업이 갖는 가치를 인식해야 합니다.
물
론 이는 화려한 프로그래밍 작업은 아닙니다. 변형을 깔끔하게 캡슐화하고 향후 확장이 가능한 형태로 여러 구성 요소를 완벽하게
설계하는 작업은 설레는 일입니다. 프로그래머는 정확함을 좋아하며, 모든 조각을 정확하게 끼워 맞추는 작업은 멋진 일입니다.
그러나 소프트웨어 개발의 많은 부분에서 개발자들은 숙련공처럼 작업해야 합니다. 코드 검토, 단위 테스트 작성, 주석 정리가
여기에 해당됩니다. 고객은 개발자들이 고객의 개인 정보를 보호하기 위해 또는 시스템을 공격으로부터 보호하기 위해 얼마나 많은
노력을 기울이는지 알지 못하겠지만 개발자들 스스로는 그 가치를 잘 알고 있습니다. 또한 성능 최적화나 전원 관리와 같이 개발자의
'진정한 능력'이 필요한 영역들도 있습니다. 우리가 가진 기술과 경험을 이용해 당면한 문제를 해결하는 것과 같이 이러한 작업은
높은 수준의 아키텍처가 아니라 눈앞의 작업입니다.
필
자는 설계자가 아닌 개발자라는 점에 자부심을 느낍니다. 언젠가 모든 소프트웨어 엔지니어링 문제를 해결하게 되면 그때는 우리 모두
설계자가 될 수 있을 것입니다. 그동안에는 잘 다듬어진 소프트웨어를 완성하는 것이 우리가 할 일입니다.
Adam Barr는
13년 동안 Microsoft에서 일해 왔으며, 개발자와 프로그램 관리자를 거쳐 현재는 Engineering Excellence
팀의 지식 엔지니어로서 개발 엔지니어링 프로세스를 지원하기 위한 내부 컨설턴트이자 강사로 활동하고 있습니다.
Unified Modeling Language™ (UML®)
NOTE: Version 2.0 does not have XSD or XML associated files due to structural problems with the UML metamodel.
The current version is found at http://www.omg.org/spec/UML/Current
|
||
| 2.3 | May 2010 | http://www.omg.org/spec/UML/2.3 |
| 2.2 | February 2009 | |
|
2.1.2 |
November 2007 |
|
|
2.1.1 |
August 2007 |
|
|
Please note that version 2.1 was never released as a formal specification |
||
|
2.0 |
July 2005 |
|
|
1.5 |
March 2003 | |
|
1.4.2 |
July 2004 |
see ISO/IEC 19501 |
|
1.4 |
September 2001 | |
|
1.3 |
March 2000 | |
iSO Released Versions of UML
| ISO Number | Release date | UML Version | Format | URL |
| ISO/IEC 19501 | January 2005 | 1.4.2 | http://www.omg.org/spec/UML/ISO/19501/PDF | |
| PostScript | http://www.omg.org/spec/UML/ISO/19501/PS |
from: http://www.raymond.cc/blog/archives/2010/07/19/access-pandora-radio-outside-of-usa-ip-hider/
Normally I’m not one that supports or uses proxies myself, seeing as I usually can access 99% of what I need and want on the internet without the use of them. However, because I live in Canada and not in the United States, I can not access certain sites or certain Youtube videos without the stereotypical “This video can not be shown in your country”. And I’m sure the majority of us have seen it as well: the fact that we are not allowed to certain things only because our countries are not seen as equals. A prime example of this is with Pandora Radio: in Canada, we can not access it because of having less restrictive copyright. However, my American friends can access it fine. And at the same time, in the European Union, they have an application called ‘Spotify’, that if you aren’t aware of, is a streaming radio application for your desktop that you have to sign up for… but can only sign up and use if you’re in the EU. And despite the fact that, yes, I could move to these countries when I get older… why on Earth would I do that if I enjoy Canada?
Access Pandora Radio Outside of USA: IP Hider
Author: Paul\HellNoire19 Jul
Normally I’m not one that supports or uses proxies myself, seeing as I usually can access 99% of what I need and want on the internet without the use of them. However, because I live in Canada and not in the United States, I can not access certain sites or certain Youtube videos without the stereotypical “This video can not be shown in your country”. And I’m sure the majority of us have seen it as well: the fact that we are not allowed to certain things only because our countries are not seen as equals. A prime example of this is with Pandora Radio: in Canada, we can not access it because of having less restrictive copyright. However, my American friends can access it fine. And at the same time, in the European Union, they have an application called ‘Spotify’, that if you aren’t aware of, is a streaming radio application for your desktop that you have to sign up for… but can only sign up and use if you’re in the EU. And despite the fact that, yes, I could move to these countries when I get older… why on Earth would I do that if I enjoy Canada?
So this is where proxies have to come in. And I’ve recently been looking at different applications, such as Tor and The JAP Project/JonDo
though neither fully worked, either timing out, erroring for no reason,
or randomly timing out. The JAP Project seems a lot more stable and
safe, though rather then facing though errors, I notice my 1.5 mb
connectivity dropping to next to nothing.
Until I tried IP Hider that is. I’m actually impressed.

Picture of the main screen
I have never had an easier time with setting up a proxy in my life. Simply install the application, select the shortcuts you’d like set up, and reboot. By default, it will autostart with Windows, then you just need to update it, and select the country you’d like a proxy from. It will automatically enable the proxy server in the country you selected. As you can see by the screenshot above, I went and tried it out, setting myself up to work in the USA. I then tried to access Pandora Radio and certain Youtube videos I knew wouldn’t work in Canada, such as Dire Strait’s Money for Nothing. Both, while slightly slower then my normal connectivity due to it being routed though the proxy, worked perfectly fine.
And now I offer a gift for those who would also like to take advantage of this easy-to-use proxy. I’m going to give away five licenses for one year for IP Hider, to be drawn up on Friday, the 23th. I feel that this program is a really nice way to access sites or materials that are outside of your country, so rather then deal with free proxies, it might be wiser to try and win one of the licenses! Best of luck to all who enter!
[펌] 개인과외소득신고-개인과외교습자소득신고에 관하여 낙서장 2009/08/13 01:09 복사 http://blog.naver.com/susieye/60088331932
유용한 잡동사니 2010. 7. 19. 15:03
낼 세금이 없다하더라도 소득신고는 꼭 해야한다 매년 5월31일은 전년도1월1일부터 12월31일까지 벌어들인 수업료즉, 소득금액확정신고기한이다. 익년 5월 중순부터 5월31일까지 거주하는 세무서에 가서 소득신고를 하면 된다. 신고는 인터넷접수도 가능하다. 서식은 국세청홈페이지에 가셔서 다운받으면 되는데 전문지식이 없으면 그냥 직접 세무서에 가서 세무공무원의 도움을 받는 것도 좋다.
개인과외교습신고와 소득신고는 별개다 개인과외교습신고는 교습지관할교육청에다 하고, 소득신고는 관할세무서에 한다
사업자가 사업자등록을 하지않고 사업행위을 하면 범법이듯이 개인과외교습자가 교습신고를 하지 않고 교습행위를 하면 범법이다
또한 사업자가 1.1-12.31일까지의 소득을 다음해 5월말에 소득신고하듯이 개인과외교습자도 1.1-12.31일까지의 소득을 다음해 5월말까지 다른소득이랑 합산신고한다 소득신고를 하지 않거나 누락할 경우 과태료가 붙는다
그런데 여기서 중요한 포인트가 있다. 교육청에 작성제출시 신고한 금액은 다음해 5월에 소득(금액확정)신고할때의 금액과는 별개이다. 교육청에 제출하는 것은 말 그대도 내가 과외를 하고있다는 것만을 의미한다. 즉, 과외를 그만하게 된다거나 할 때 변경신고를 또 교육청에다 하는것이 원칙이지만 하는 사람은 대한민국에 아무도 없지싶다. 즉, 정확한 소득부분은 5월말 소득신고시에 성실히 하면된다. 국세청은 납세자에게 '성실납부자'로 추정하기 때문에 세무서에 가서 소득금액을 신고한 금액이 곧 세액산출의 직접적인 근거가 된다. 따라서 과외교습자신고시 과외수업료금액과 소득신고시 소득금액신고와는 무관하다는 것을 다시한번 강조한다
* 과외수업료는 기타소득에 해당된다. 기타소득은 강연료,복권당첨금,전속계약금 등 비정기적인 수입원이다. 그래서 나머지 이자소득,배당소득,부동산임대소득,사업소득,근로소득,연금소득퇴직소득,양도소득까지 있다면 총 9가지 소득을 합산 신고하면 되고, 과외 소득만 있다면 그것만 하면 된다
(예) 매월 30만원의 수입액은 1년합산 360만원입니다.
부양가족이 한명도 없고 기타다른소득공제되는게 없는 경우를 가정하면
총수입금액 : 360만원 - 필요경비 : 288만원(기타소득금액중 과외비는 80%를 필요경비인정하므로 360만*80%) 소득금액 : 72만원 (총수입금액-필요경비=360만-288만) - 소득공제 : 160만원 (기본공제 : 각100만 , 특별공제(본인) : 60만) 과세표준 : 0원 (과세표준=소득금액-소득공제가 마이너스가 되므로 과세표준은 0으로 본다) 즉, 납부할 세액은 과세표준액* 세율 = 0 * 세율 = 0 이다 즉, 과외수입으로 세금을 납부하려면 소득금액이 160만원, 즉 총수입금액이 800만원을 초과하여야 하며, 그 초과금액에 대해서만 누진세율을 곱하여 납부할 세액이 결정된다
출처 : 이룸교육
 |
출처: 공병호의 레터
|
from: http://blog.naver.com/polydalai?Redirect=Log&logNo=30009309147
2006.10월 작성
2006.10월 작성
| 세계 반도체 장비 산업 현황 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
반도체 장비 산업은 반도체 칩 제조 산업에 있어 중요한 부분을 차지하고 있는데, 반도체 칩 제조업체들은 매출액의 약 20 % 정도를 반도체 장비 구입에 쓰고 있다. 반도체 장비 산업은 예전에는 반도체 칩 산업에 있어서 별로 중요하지 않은 부문으로 인식되었지만 반도체 산업이 발전함에 따라 장비 산업의 중요성이 점점 높아지고 있으며 예전에는 칩 제조 업체가 주도하였던 많은 기술 개발들이 장비 업체가 주도하게 되는 일이 점차로 늘어나고 있다. 우리 나라의 경우 반도체 칩 제조 산업에 있어서는 세계에서 중요한 위치를 차지하고 있지만, 반도체 장비 산업은 상대적으로 매우 낙후된 상황이며, 국내 반도체 칩 제조 산업에 쓰이는 대부문의 반도체 장비들을 미국이나 일본, 유럽 업체들로부터 수입하고 있는 형편이다. 이번 기사에서는 세계 반도체 장비 산업의 전반, 주요 반도체 장비 업체, 반도체 장비 업체의 생존 전략, 그리고 한국의 반도체 장비 산업 현황에 대해 언급하고자 한다. 1.세계 반도체 장비 산업의 전반 세 계 반도체 장비 산업은 2002년 230억 불 정도의 시장을 형성하고 있으며, 크게 전공정 부문과 후공정 부문으로 나눌 수 있다. 전공정 부문은 실리콘 웨이퍼를 가공하여 한 웨이퍼 위에 많은 소자와 배선들을 만드는 과정이며 후공정 부문은 이러한 웨이퍼를 자르고 조립하여 개개의 칩을 만들고 이러한 칩들의 성능을 시험하는 부문이다. 전공정 부문은 장비 산업 부문의 82% 정도를 차지하고 있고 후공정 부문은 18% 정도를 차지하고 있다. 이러한 장비 산업들은 세부적으로 20-25 가지 정도로 구분할 수 있는데, 이번 기사에서는 상대적으로 큰 비중을 차지하고 있는 전공정 11 가지 부문과 후공정 2가지 부문에 대해서만 소개하고자 한다. 아래에 언급하는 처음 11가지 부문은 전공정이고 마지막 2가지 부문은 후공정에 해당한다. 1.1. 이온 주입 공정 (2.8 %) (괄혼 안의 퍼센티지는 전체 장비 시장에서 차지하는 대략적인 비중을 나타낸다.) 이 온 주입 공정은 반도체 트랜지스터를 제작할 때 불순물을 주입하는 공정이다. 대표적인 장비 업체로는 엑셀리스 (Axcelis) (37 %), 베리안 (Varian) (31 %), 어플라이드 머티리얼즈 (Applied Materials) (25 %) 등이 있다 (괄호 안의 퍼센티지는 시장 점유률). 1.2. 화학적 증착 공정 (11.2 %) 화학적 증착 공정은 반도체 공정 전반에 걸쳐서 여러 번 이용되는 박막 제조 공정이며 상대적으로 장비 시장에서 차지하는 비중도 크다. 대표적인 장비 업체로는 어플라이드 머티리얼즈 (52%), 노벨러스 (Novellus) (24%), 도쿄 일렉트론 (Tokyo electron) (10%) 등이 있다. 1.3. 물리적 증착 공정 (3.8 %) 물리적 증착 공정은 반도체 공정 전반에 걸쳐서 이용되고 있는 박막 제조 공정이며, 대표적인 업체로는 어플라이드 머티리얼즈 (70%), 울벡 (Ulvac) (10%), 노벨러스 (7 %) 등이 있다. 1.4. 화학적 기계적 평탄화 공정 (2.3 %) 화 학적 기계적 평탄화 공정은 최근 들어 배선이 알루미늄에서 구리로 바뀌는 과정에서 중요도가 급속히 커지는 과정에 있는 공정으로 웨이퍼의 표면을 평탄화 시켜주는 공정이다. 대표적인 업체로는 어플라이드 머티리얼즈 (60%), 이바라 (Ebarra) (23%) 노벨러스 (8%) 등이 있다. 1.5. 트랙 (track) 공정 장비 (3.7 %) 트랙 공정은 박막을 만드는 한 방법인데 액상의 재료물질을 웨이퍼 위에 떨어뜨린 후 웨이퍼를 빠르게 회전시켜서 균일한 박막을 만드는 방법이다. 주로 포토 리지스트 박막 제조 시 많이 쓰인다. 대표적인 업체로는 도쿄 일렉트론 (83%), 대니폰 스크린 (Dainippon Screen) (8%), ASML (4%) 등이 있다. 1.6. 노광 장비 (12 %) 노광 장비는 포토 리지스트에 패턴을 만드는 과정으로 반도체 칩 발달에 있어서 병목이 되고 있는 기술이며 최근 들어 전체 장비 비용에서 차지하는 비중이 점차로 커지고 있다. 대표적인 업체로는 ASML (54%), 니콘 (nikon) (27%), 캐논 (Canon) (18%) 등이 있다. 1.7. 노광 마스크 제조 장비 (12 %) 노광 마스크 제조 장비는 노광을 하기 위한 마스크를 만드는 공정인데, 대표적인 업체로는 대니폰 프린팅 (Dainppon printing) (22%), 듀폰 포토마스크 (DuPont Photomasks) (20 %), 포토닉스 (20 %) 등이 있다. 1.8. 웨이퍼 세척 장비 (3.6 %) 웨 이퍼 세척 장비는 박막 제조나 식각 제조 공정 후에 웨이퍼를 세척해주는 공정으로 상대적으로 낮은 기술이 요구되는 공정이며, 따라서 여러 군소 업체들이 시장을 나누어 점유하고 있다. 대표적인 업체로는 대니폰 스크린, SEZ, SCP, FSI, 맷슨 테크날러지 (Mattson technology), 세미툴 (Semitool) 등이 있다. 1.9. 식각 공정 장비 (3.6 %) 식 각 공정은 공정의 꽃이라 불릴 만큼 기술적으로 어려운 공정으로 인식되고 있으며 상대적으로 장비의 가격보다는 성능에 의해서 시장 점유율이 좌우되고 있는 공정이다. 대표적인 업체로는 램 리서치 (Lam Research) (28 %), 도쿄 일렉트론 (27 %), 어플라이드 머티리얼즈 (27%) 등이 있다. 1.10. 측정 장비 (9.8 %) 박막, 노광, 식각 공정이 끝난 뒤에는 이들을 검사하고 측정할 수 있는 장비가 필요한데, 이러한 장비를 측정 장비라고 한다. 대표적인 업체로는 KLA Tencor (48 %), 히타지 (hitachi) (11 %), 어플라이드 머티리얼즈 (11 %) 등이 있다. 1.11. 공장 자동화 (5.2 %) 위에서 언급한 공정 장비들의 한 공정 후에 다음 공정으로 이행 시 웨이퍼들의 운반을 자동으로 해주거나 각 공정 장비들의 제어를 자동화 할 수 있는 설비 등을 일컫는다. 대표적인 업체로는 부룩스 오토매이션 (Brooks Automation) (30 %), Asyst technology (21 %) 등이 있다. 1.12. 시험 장비 (8.2 %) 시 험 장비는 전공정에서 가공한 웨이퍼를 시험하거나 조립후의 반도체 칩을 시험하는 장비들을 일컫는다. 대표적인 업체로는 어드팬테스트 (Advantest) (35 %), 테러다인 (Teradyne, 26 %), 에질런트 (Agilent) (18 %) 등이다. 1.13. 조립 및 포장 장비 (9.8 %) 가 공된 반도체 웨이퍼를 잘라서 최종적인 칩을 만드는 장비이다. 상대적으로 낮은 기술을 요구하는 부분이고 따라서 여러 군소 업체들이 시장을 나누어 갖고 있다. 대표적인 업체로는 ASM international (12 %), KNS (12 %), Tokyo Seimetsu, (10 %), ESEC (8 %) 등이 있다. 2. 주요 반도체 장비 업체 2.1. 반도체 장비 산업의 현재와 과거 반 도체 장비 산업은 최근 20년간 비약적인 발전을 거듭해 왔다. 1982년의 장비업체들의 매출액과 2002년의 매출액을 비교해 보면 10배 이상의 성장을 보여주고 있고 주요 업체들의 순위 또한 심하게 변동된 것을 알 수 있다 (표1 참조). 최근 20년간 반도체 업체들 중 가장 성공한 업체를 꼽으라면 대부분 어플라이드 머티리얼즈를 언급하고 있는데 어플라이드 머티리얼즈는 기술력이 좋은 소형 업체를 합병하여 새로운 시장에 진입하는 방법으로 1장에서 언급한 반도체 전공정 장비 시장 중 대부분의 시장에 성공적으로 진입하였으며 이를 바탕으로 비약적인 성장을 이루었다.
2.2. 반도체 장비 산업의 미래 반 도체 장비 산업은 급속히 성장하고 있는 산업인 만큼 업체들간의 경쟁도 매우 치열하고 인수, 합병이 매우 활발히 일어나고 있으며 또한 표 1에서 보여주는 것처럼 업체들간의 순위변동도 빠르게 변하고 있다. 지금 현재 장비업체 산업에서 압도적으로 선두를 달리고 있는 어플라이드 머티리얼즈도 1984년에는 10대 업체에도 끼지 못할 만큼 어려움을 겪었었고 그 후 기술력 있는 작은 업체를 합병하는 방식으로 급속히 성장하였으나 성장 배경이 기술력을 바탕으로 시장 점유율을 높여나갔던 것이 아니라 작은 업체를 합병하여 새로운 시장에 진입하는 방법으로 성장하였고 앞의 1장에서 설명하였던 것처럼 노광을 제외한 거의 모든 시장에 이미 진입하였기 때문에 앞으로의 계속적인 성장을 보장하기는 어려운 상황이다. 따라서 앞으로 반도체 시장의 미래는 어플라이드 머티리얼의 계속적인 성장 여부, 그리고 현재 어플라이드 머티리얼과 맞서기 위해 협력관계를 이루며 경쟁하고 있는 회사들이 합병을 하여 또 다른 대형 장비 업체를 만들어 낼 지에 대해 많은 관심이 모아지고 있다. 3. 반도체 장비 업계의 생존 전략 반도체 장비 업체들의 전략에 영향을 미치는 요소는 크게 기술 동향 및 시장 동향 두 가지로 나눌 수 있다. 3.1. 기술 동향 반 도체 산업에 이용되고 있는 기술들 중에는 점점 사라져 가는 기술이 있는가 하면 새로이 나타나는 기술도 있다. 예를 들면 예전에는 소자의 배선으로 알루미늄이 많이 쓰였지만 점차로 구리 배선으로 바뀌고 있는 과정이고 따라서 이에 관련된 공정도 많이 바뀌고 있다. 알루미늄 배선을 이용할 때는 알루미늄을 식각하고 유전체 박막을 식각된 알루미늄 사이로 증착하는 기술이 주로 이용되었지만 구리 배선에서는 유전체를 식각하고 구리를 유전체 사이로 증착하는 기술이 주로 이용되고 있다. 장비 산업 업체가 생존하기 위해서는 이러한 기술 동향을 잘 파악하여 미래에 이용될 기술에 관련된 장비 개발에 주력하는 것이 매우 중요하다. 3.2. 시장 동향 반 도체 장비 산업은 설비 산업이기 때문에 상대적으로 경기에 매우 민감한 산업이다. 따라서 장비 업체들은 전반적인 경제 지표에 예측에 매우 민감하게 반응하며 신제품 개발이나 인력 조절을 하고 있다. 또한 장비 업계의 고객인 반도체 칩 제조업체들의 동향도 매우 자세히 주시하며 전략을 세우고 있다. 반도체 장비 산업은 1990년대에는 개인용 컴퓨터 산업이 급속히 발달하면서 디램이나 마이크로 프로세서를 제조하는 회사들에 장비를 납품하며 성장하였는데 최근에는 휴대폰 산업이 급속히 발전하면서 휴대폰에 이용되는 로직 칩들을 제조하는 회사들을 점점 중요시하고 있다. 반도체 장비 산업을 언급 할 때 빼놓을 수 없는 것이 반도체 칩 제조 업체들의 동향인데 현재 장비 산업에서 중요히 생각하고 있는 칩 제조 업체들의 동향을 [표 2]에서 소개하였다.
4. 한국의 반도체 장비 산업 한 국의 반도체 장비 산업은 위에 언급한 사실들에서 알 수 있듯이 선진국들에 비해서 많이 뒤떨어져 있는 상황이다. 하지만 표 2에서 보듯이 한국의 반도체 산업이 세계 반도체 산업에서 차지하는 높은 비중을 고려해 본다면 한국의 장비 산업은 큰 잠재력이 있다고 할 수 있다. 또한 현재 세계 장비 산업을 점유하고 있는 미국, 일본, 유럽보다 상대적으로 인건비가 싸고 연구인력이 우수하기 때문에 장비 산업의 성공 가능성도 높다고 볼 수 있다. 그러나 한편으로는 반도체 장비 산업은 높은 기술력을 바탕으로 세계 시장을 일정 부문 점유하지 않으면 기술 개발을 위한 연구비 조달이 어렵기 때문에 후발업체가 새로이 반도체 시장에 진입하기는 매우 어려운 상황이다. 이러한 사실들을 고려해 볼 때 한국에 적당한 반도체 장비 산업 전략은 상대적으로 적은 기술력을 필요로 하는 장비 산업을 집중 육성하여 수입 대체 효과를 거두는 방법이나 또는 새로이 출현하고 있는 반도체 공정 기술을 실현할 수 있는 장비 산업 분야에 집중적으로 투자하는 것이 적절한 방법일 것 같다. 사실 이러한 접근 방법은 이미 상당 부분 성공을 거두고 있는데, 예를 들어, 상대적으로 낮은 기술을 요구하는 포토 리지스트 에싱 공정이나 새로이 출현하고 있는 원자 층 박막제조 공정에서는 한국의 소형 반도체 업체들이 주목할 만한 성공을 거두고 있다. 5. 참고문헌 이번 기사에서 언급한 전반적인 반도체 시장이나 업체들의 동향에서 언급된 수치들은 아래에 언급한 인터넷 홈페이지에 나와 있는 자료와 기사들을 참고로 하여 작성하였다. 각 홈페이지들에 나와 있는 자료들 간에는 서로 조금씩 틀린 부분도 있었는데 이러한 경우에는 평균적인 수치를 언급하려고 노력하였다. [1] VLSI Research 홈 페이지 (www.vlsiresearch.com) [2] Semiconductor Industry Association 홈 페이지 (www.siimichips.org) [3] Dataquest 홈페이지 (www.gartner.com) [4] Silicon stragegies 홈페이지 (www.siliconstrategies.com) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
세마포어 [ semaphore ]
스레드들 간에서 공유가 배제되는 객체. 파일과 같은 공유 자원이 수행 중 오직 한 프로그램이나 스레드에 게만 소유되어야 할 필요가 있을 때 그 자원에 대한 뮤텍스 객체를 생성시킨다. 뮤텍스가 비신호 상태이면 프로그램은 자원을 점유하여 사용한 후 이를 반환하고, 다른 프로그램 또는 다른 스레드가 자원을 사용 중 즉, 뮤텍스가 신호 상태이면 대기 상태로 들어가 끝나기를 기다린다. 뮤텍스는 여러 면에서 크리티컬 섹션과 비슷하고, 대신 사용할 수도 있지만 이름을 가질 수 있다는 점에서 크리티컬 섹션보다 우월하다.from: http://blog.naver.com/cosmical?Redirect=Log&logNo=60060170999
두 용어는 비슷하게 생겨서 꽤나 헷갈린다.
사전적 의미를 알아보면..
Override: ~보다 우위에 서다. ~을 넘어서까지 퍼지다. ~을 무효로 하다.
Overload: ~에 짐을 너무 많이 싣다. 부담을 너무 많이 지우다.
사전의 의미만 봐도 대충 감이 온다. override를 하면 이전에 정의한 함수를 무효로 하고 새로 정의한 내용으로 쓰겠다는 의미일거고, overload는 중복해서 정의해서 사용을 하겠다는 의미가 될 것이다.
이제 저 두 용어가 C++에서는 어떤 개념으로 사용되는지 알아보자. (참조: Teach Your Self C++ in 21Days)
Override와 Overload는 [chapter 12. 상속]에 나온다.
아래의 12.4의 예제코드를 보면.. 파랑색으로 되어 있는 부분이 있다.
Dog이라는 클래스는 Mammal이라는 클래스를 상속했다.
그러면서 Dog클래스의 생성자를 overload해서 여러 개 선언을 했다. 별도로 설명은 하지 않겠다.
1: //Listing 12.4 Overloading constructors in derived classes
2:
3: #include <iostream.h>
4: enum BREED { YORKIE, CAIRN, DANDIE, SHETLAND, DOBERMAN, LAB };
5:
6: class Mammal
7: {
8: public:
9: // constructors
10: Mammal();
11: Mammal(int age);
12: ~Mammal();
13:
14: //accessors
15: int GetAge() const { return itsAge; }
16: void SetAge(int age) { itsAge = age; }
17: int GetWeight() const { return itsWeight; }
18: void SetWeight(int weight) { itsWeight = weight; }
19:
20: //Other methods
21: void Speak() const { cout << "Mammal sound!\n"; }
22: void Sleep() const { cout << "shhh. I'm sleeping.\n"; }
23:
24:
25: protected:
26: int itsAge;
27: int itsWeight;
28: };
29:
30: class Dog : public Mammal
31: {
32: public:
33:
34: // Constructors
35: Dog();
36: Dog(int age);
37: Dog(int age, int weight);
38: Dog(int age, BREED breed);
39: Dog(int age, int weight, BREED breed);
40: ~Dog();
41:
42: // Accessors
43: BREED GetBreed() const { return itsBreed; }
44: void SetBreed(BREED breed) { itsBreed = breed; }
45:
46: // Other methods
47: void WagTail() { cout << "Tail wagging...\n"; }
48: void BegForFood() { cout << "Begging for food...\n"; }
49:
50: private:
51: BREED itsBreed;
52: };
아래의 12.5의 예제 코드는 override를 보여준다.
Dog클래스는 Mammal이라는 클래스를 상속받았다. 그러면서 Mammal의 Speak라는 함수를 override해서 사용하는 것이다. (예제코드는 컴파일이 되도록 수정을 했다. VS 2005기준)
#include <iostream>
enum BREED { YORKIE, CAIRN, DANDIE, SHETLAND, DOBERMAN, LAB };
class Mammal
{
public:
// constructors
Mammal() { std::cout << "Mammal constructor...\n"; }
~Mammal() { std::cout << "Mammal destructor...\n"; }
//Other methods
void Speak()const { std::cout << "Mammal sound!\n"; }
void Sleep()const { std::cout << "shhh. I'm sleeping.\n"; }
protected:
int itsAge;
int itsWeight;
};
class Dog : public Mammal
{
public:
// Constructors
Dog(){ std::cout << "Dog constructor...\n"; }
~Dog(){ std::cout << "Dog destructor...\n"; }
// Other methods
void WagTail() { std::cout << "Tail wagging...\n"; }
void BegForFood() { std::cout << "Begging for food...\n"; }
void Speak()const { std::cout << "Woof!\n"; }
private:
BREED itsBreed;
};
// 코드 옆에 주석 부분이 그 줄을 실행했을 때 나온 결과이다.
int _tmain(int argc, _TCHAR* argv[])
{
Mammal bigAnimal; //Mammal constructor...
Dog fido; //Mammal constructor...
//Dog constructor...
bigAnimal.Speak(); //Mammal sound!
fido.Speak(); //Woof!
return 0; //Dog destructor...
//Mammal destructor...
//Mammal destructor...
}
결과를 보면..bigAnimal은 Mammal클래스이므로 Speak를 호출했을 때 "Mammal sound!"를 출력한다. 그러나 fido는 Dog클래스이고, Dog클래스는 Speak함수를 override하였으므로 "Mammal sound!"대신에 "Wood!"를 출력한다. 즉, Mammal의 Speak함수가 무시된 것이다.


from: http://blog.reeze.com/entry/%EC%B7%A8%EC%97%85%EC%8B%9C-%EA%B0%9C%EB%B0%9C%EC%9E%90%EB%93%A4%EC%9D%B4-%ED%94%BC%ED%95%B4%EC%95%BC-%ED%95%A0-%ED%9A%8C%EC%82%AC
취업시 개발자(프로그래머)들이 피해야 할 회사
2010/06/18 15:23 / 프로그래머로 살아가기요즘 취업하기가 참 어렵다고 합니다.
신입은 물론이고 경력직까지 뽑는데도 별로 없는 상황인데요.
이럴때일수록 급하다고 아무 회사나 덜컥 들어가는 경우가 많은것 같습니다.
절박한 심정이야 이해를 못하는 것은 아닙니다만, 한번 입사를 하면 평생동안 자신의 경력에 포함이 되는 선택이므로 신중에 신중을 기해야 합니다.
특히 신입들은 첫 직장이 매우 중요합니다.
그것은 개발이든 다른 직종이든 마찬가지입니다.
경험이 부족하기 때문에 회사를 고르는 기준이 없거나 판단을 잘 못하기도 합니다.
그런분들을 위하여 몇가지 조심해야 할 회사 유형을 적어봅니다.
1. 자주 구인 광고를 내는 회사
회사가 발전하여 직원이 늘어나는 경우에는 문제가 아닙니다만, 매출이 늘거나 발전하는 것 같지는 않은 회사인데, 취업 사이트를 보면 거의 맨날 구인중이라는 공고가 올라오는 회사들이 있습니다.
이런 회사는 십중 팔구는 비전을 찾기가 힘들고 박봉에 야근으로 부려먹고 직원들이 입사후 얼마후에 관두는 경우가 많은 즉 이직율이 높은 회사일 확율이 높습니다.
좋은 대우를 해주고 비전이 있는 회사인데 그만두는 사람이 많을리는 없겠죠.
2. 개발자가 아닌 사람이 1차 면접을 보는 회사
개발팀장이나 개발 직군을 가진 사람이 아닌 사람이 개발자의 1차 면접을 보는 회사가 있습니다.
이런 회사들은 대부분 개발조직이 힘이 없거나 개발 조직은 상당히 하위 조직으로 포지셔닝된 회사입니다.
대부분 말도 안되는 일정의 쪼임을 당하거나 퀄리티 보다는 단순 반복 노가다를 반복하여 발전할 기회가 없는 회사일 가능성이 높습니다.
3. 기술력보다는 회사 규모나 인맥을 강조하는 회사
우리회사는 매출이 얼마, 정부 기관과 연줄이 있고.. 등등.
면접때 회사의 규모나 인맥을 강조하는 회사들이 있습니다.
이런 회사는 R&D에 대한 투자보다는 영업비를 더 많이 쓰는 , 그러다가 연줄이 끊기면 회사가 문을 닫아야 하는 경우가 발생할 확률이 높은 회사입니다.
4. 인력 파견 회사
첫직장 만큼은 단기 프로젝트로 인력 파견을 하는 회사는 피하라고 말씀드리고 싶습니다.
인력 파견 회사는 말그대로 소모품입니다. 인력 파견회사들이 신입을 잘 쓰지도 않지만 첫 직장 만큼은 자체 서비스를 하는 회사나 자체 솔루션을 개발하는, 스스로 발전할 수 있는 회사를 선택하라고 조언드리고 싶네요.
기타 여러가지 유형이 있고 상황마다 다르겠지만 제가 그동안 봐온 피해야할 회사들의 유형을 정리해보았습니다.
부디 신중하게 좋은 결정들 하시기 바랍니다.
출처: http://blog.naver.com/phrack?Redirect=Log&logNo=80040464488
출처: e-campus 쉽게 따라 배우는 UML
UML 1.3의 다이어그램
빨간색이 실제 다이어그램
흰색은 실존하지 않는 분류

UML 2.0의 다이어그램
이탤릭은 실존하지 않는 분류
빨간색은 새로 추가된 다이어그램
- Composite Structure Diagram
- Package Diagram
- Interaction Overview Diagram
- Timing Diagram
파란색은 이전 1.3의 다이어그램에서 이름이 바뀐 것
- Collaboration Diagram > Communication Diagram
- Statechart Diagram > State Machine Diagram

My) 총 14 개 = Structure쪽 7 개 + Bahavior쪽 7개.
발췌: http://en.wikipedia.org/wiki/Unified_Modeling_Language

발췌: http://en.wikipedia.org/wiki/Unified_Modeling_Language
Diagrams overview
UML 2.2 has 14 types of diagrams divided into two categories.[11] Seven diagram types represent structural information, and the other seven represent general types of behavior, including four that represent different aspects of interactions. These diagrams can be categorized hierarchically as shown in the following class diagram:
from: http://cafe.naver.com/javacs.cafe?iframe_url=/ArticleRead.nhn%3Farticleid=28
3.stack과 heap의 차이점 (heap도 자료주고의 heap정렬로 생각했는데 잘..흠)
가장 큰 차이는 stack은 LIFO의 형태이다. Heap은 그냥 메모리 공간이다. stack은 주로 작업할때 데이터를 임시 저장하는 용도로 사용한다. 함수내부의 local변수들은 stack을 이용한다. 함수가 호출되면 stack에 함수 반환시 돌아올 주소영역을 저장하고, 함수에서 쓸 local변수들 크기만큼 할당을 받는다. 다시말해서 local 변수들은 stack을 이용하는 것이다. 함수가 반환되면 이 stack영역은 자동으로 삭제가 된다.
heap은 주로 프로그램 시작시 할당할 크기를 결정할 수 없고 동적으로 할당해야 할 필요가 있을 때를 위한 메모리 영역으로써 사용자가 직접 할당하고 해제해 주어야 하는 메모리 영역이다.
출처: http://blog.naver.com/swjo207?Redirect=Log&logNo=100070903497
프로그램이 메모리에 올라간 모습을 간단하게 살펴보면,
크게 Data Segment와 Code Segment로 나누어 볼 수 있습니다.
즉, 데이터 영역과 동작을 정의한 코드 영역으로 나뉘어 있는 모습이죠.
stack과 heap은 이 Data Segment영역을 이용하게 됩니다.
(어떤 경우엔 Stack Segment가 따로 나뉘어 존재하기도 합니다)
보통 stack은 Data Segment의 처음 영역에서 부터 할당이 되고
heap은 Data Segment의 끝 영역에서 부터 할당이 됩니다.
(반대의 경우도 있습니다)
기본적으로 이 둘의 차이는 자동으로 생성, 제거되는 휘발성의 특성을
갖느냐 그렇지 못 하느냐의 차이가 있습니다.
일반적으로 global이나 static변수들은 heap의 첫부분에 위치하고 있다고
보시면 됩니다. 절대 지워지는 일이 없죠. 또한 malloc()으로 동적 할당
받는 경우에도 heap을 이용하게 됩니다. 나중에 free()하면 다시 그영역
을 쓸 수 있게 됩니다.
그에 비해 함수내부의 local변수들은 stack을 이용합니다. 함수가 호출
되면 stack에 함수 반환시 돌아올 주소영역을 저장하고, 함수에서 쓸
local변수들 크기만큼 할당을 받습니다. - 다시말해서 local 변수들은
stack을 이용하는 것 입니다. 아시다시피 함수가 반환되면 이 stack영역은
자동으로 삭제가 됩니다.
프로그램이 메모리에 올라간 모습을 간단하게 살펴보면,
크게 Data Segment와 Code Segment로 나누어 볼 수 있습니다.
즉, 데이터 영역과 동작을 정의한 코드 영역으로 나뉘어 있는 모습이죠.
stack과 heap은 이 Data Segment영역을 이용하게 됩니다.
(어떤 경우엔 Stack Segment가 따로 나뉘어 존재하기도 합니다)
보통 stack은 Data Segment의 처음 영역에서 부터 할당이 되고
heap은 Data Segment의 끝 영역에서 부터 할당이 됩니다.
(반대의 경우도 있습니다)
기본적으로 이 둘의 차이는 자동으로 생성, 제거되는 휘발성의 특성을
갖느냐 그렇지 못 하느냐의 차이가 있습니다.
일반적으로 global이나 static변수들은 heap의 첫부분에 위치하고 있다고
보시면 됩니다. 절대 지워지는 일이 없죠. 또한 malloc()으로 동적 할당
받는 경우에도 heap을 이용하게 됩니다. 나중에 free()하면 다시 그영역
을 쓸 수 있게 됩니다.
그에 비해 함수내부의 local변수들은 stack을 이용합니다. 함수가 호출
되면 stack에 함수 반환시 돌아올 주소영역을 저장하고, 함수에서 쓸
local변수들 크기만큼 할당을 받습니다. - 다시말해서 local 변수들은
stack을 이용하는 것 입니다. 아시다시피 함수가 반환되면 이 stack영역은
자동으로 삭제가 됩니다.
출처: http://blog.naver.com/ttagui?Redirect=Log&logNo=10052778539
출처: KLDP http://kldp.org/node/199
================================================================================
Submitted by arimae
W.Richard Stevens 씨께서 저술한 Advanced Programming in the Unix Environment 의 7.6절은 보면 C 프로그램의 Layout에 대해 설명이 나와있습니다.
간단히 설명해 보면
/-------------------------/ 메모리상에서
| | 높은 구역
| Stack |
| |
/-------------------------/
| |
| Heap |
| |
/-------------------------/
| Uninitialized data |
| ---------Data---------- |
| Initialized data |
/-------------------------/
| |
| Text |
| | 메모리상에서
/-------------------------/ 낮은 구역
Text segment : CPU에 의해 실행되는 머신 코드들이 있는 영역.Read Only
Initalized data segment : data segment 라 불리는 영역이며, 초기화된 외부 변수 static
변수등이 저장되는 영역입니다. 보통 Text segment + initialized data 영역을 합쳐서 프로그램이라고 합니다.
예) static int a = 1;
Uninitalized data segment : bss segment 라고 불리며, 이 영역을 프로그램이 실행될때 0 이나 NULL Pointer로 초기화 됩니다.
예) static int a; (외부 변수나, static 변수중 초기화 되지 않은 변수들)
Stack : 자동 변수들이 저장되는 곳이고, 함수가 호출될때 함수 안의 자동변수(함수내 로컬 변수) 등이 저장되는 곳입니다. 함수가 실행되는 동안에만 존재하며 함수의 실행이 종료되면 그 변수들도 사라집니다. 함수내의 자동 변수외에 saved frame pointer 등의 함수를 호출한 caller의 환경 정보도 저장합니다.
Heap : 동적 메모리 할당을 할경우 Heap 영역에 할당이 됩니다. Heap 영역은 uninitialzed data 영역의 top 과 stack 영역의 bottom 부분에 위치합니다.
이 밖에 더 자세한 것을 알고 싶으시면 Phrack 문서의 Smashing The Stack For Fun And Profit 을 읽어 보시거나 위에서 제가 언급한 책을 읽어 보시길 바랍니다. Phrack 문서는 해킹 문서로 해킹을 하기 전초 단계로 위의 영역에 대해 설명이 자세히 나와있습니다.
www.phrack.org 에서 받을 수 있으며, 49호 14 장이 위의 주제를 다룹니다.
==================================================================================
Submitted by 고도리
실제로는 물리적(혹은 논리적)인 메모리의 한 종류일 뿐입니다.
가장 큰 차이는 stack은 LIFO의 형태입니다. Heap은 위의 분의 프로세스
설명대로 그냥 메모리 공간입니다.
근데 왜 stack이랑 heap의 차이를 두느냐, stack은 주로 작업할때
데이터를 임시 저장하는 용도로 사용합니다.
여기에 LIFO라는 얘기가 나오게 되겠지요...
가장 간단한 예로 함수 호출을 생각해 보면, 함수를 호출하면 일단
현재 상태의 레지스터값을 저장해야하고, 함수를 호출할때 인자등을 건네
줘야합니다.
그것을 stack에 저장을 합니다. 그런 후 호출된 함수의 context쪽으로 들어
가겠지요... 여기서도 임시 저장공간으로 스택을 사용합니다.
그리고 계산을 다 한후 원래의 함수로 리턴을 해야하는데, 여기서 스택의
사용용도를 알 수가 있습니다.
일단 호출된 함수에서 사용한 값들은 다 사용을 했으니 리턴값을 빼고는 다
필요없으니 다 뽑아버리고요...
호출한 함수로 돌아가야 되니 함수호출하기 전에 저장했던 놈들을 다시
뽑아내야 되겠지요...
그래서 LIFO의 형태가 되야 하는 겁니다.
원래 컴파일러마다 함수호출관행이라는 것이 있는데, 자세한 것은
GCC manual의 해당부분을 보면 stack의 용도를 볼 수 있을 겁니다...



